![]() En résumé :
En résumé :
Au sein de la base IMOPE et dans les outils qui l’utilisent nous intégrons les Diagnostics de Performance Energétique ainsi que les informations qui leurs sont associées. Comme les DPE ne couvrent pas toutes les adresses du territoire métropolitain, nous les complétons grâce des algorithmes de prédiction.
 Méthodologie
Méthodologie
Contexte
Le Diagnostic de Performance Énergétique (DPE) est devenu un enjeu central pour les propriétaires et investisseurs. Avec l’entrée en vigueur des restrictions sur la location des passoires thermiques, il est crucial de maîtriser les subtilités de ces informations et comprendre comment la donnée peut accompagner ces enjeux.
Dans ce contexte, U.R.B.S. met à disposition deux attributs dans l’ONB : le DPE de référence officiel et le DPE de référence enrichi. L’information est complétée par l’historique des DPE, ou encore les données de conductance thermiques ou les coefficients U.
Les DPE de référence - officiels
Les DPE de référence - officiels sont issus de l’ADEME. Nous les quatre fois par an sur tout le territoire métropolitain. Ils sont disponibles gratuitement dans l’ONB.
Nous présentons pour chaque adresse possédant un DPE, un DPE dit de référence construit selon les règles suivantes :
- S’il existe un ou plusieurs DPE immeuble, nous présentons celui qui est le plus représenté ;
- Sinon, nous considérons l’étiquette la plus représentée parmi les DPE des logements de plus de 40 m².
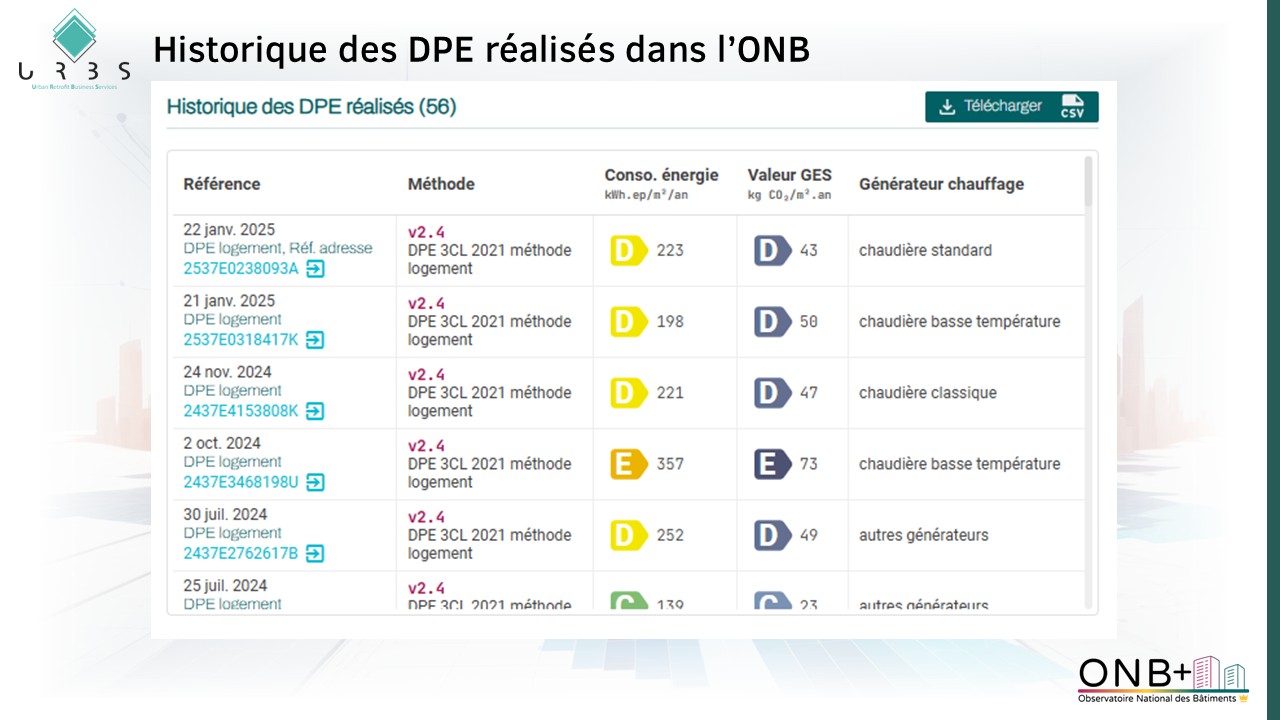
Dans la version premium nous proposons pour chaque adresse la liste et le détail des DPE réalisés.
Nous opérons plusieurs traitements pour fiabiliser, nettoyer et standardiser les adresses associées aux DPE afin que ceux-ci puissent être croisés avec toutes les données de la base IMOPE. Ce processus de fiabilisation et de standardisation des adresses constitue une étape indispensable pour l’intégration des DPE au sein de la base IMOPE et leur croisement avec les autres bases de données. Une bonne qualité d’appariement est également un préalable à la construction d’un modèle prédictif.
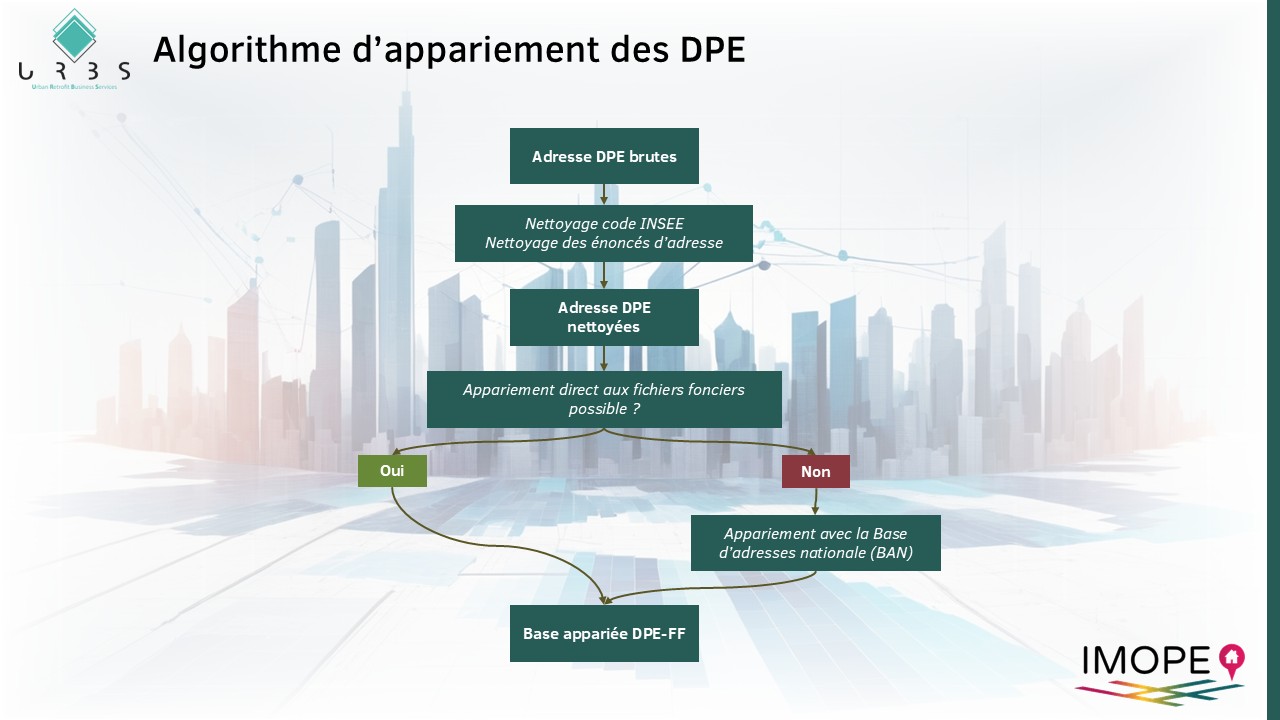
Les DPE de référence - enrichis
Les DPE de référence enrichis sont des données premium complétées par U.R.B.S : si un DPE officiel existe, il est conservé, sinon nous le simulons à l’aide d’algorithme d’apprentissage machine.
La prédiction de ces données est importante car les DPE réels ne couvrent que 13% des adresses pour 30% des logements (millésime 2025). Ce sont souvent les mêmes logements qui sont mis en location ou qui sont vendus et qui font donc l’objet d’un DPE. La complétion de cette donnée, utilisée dans les politiques en lien avec l’amélioration des performances énergétiques des logement est donc essentielle.
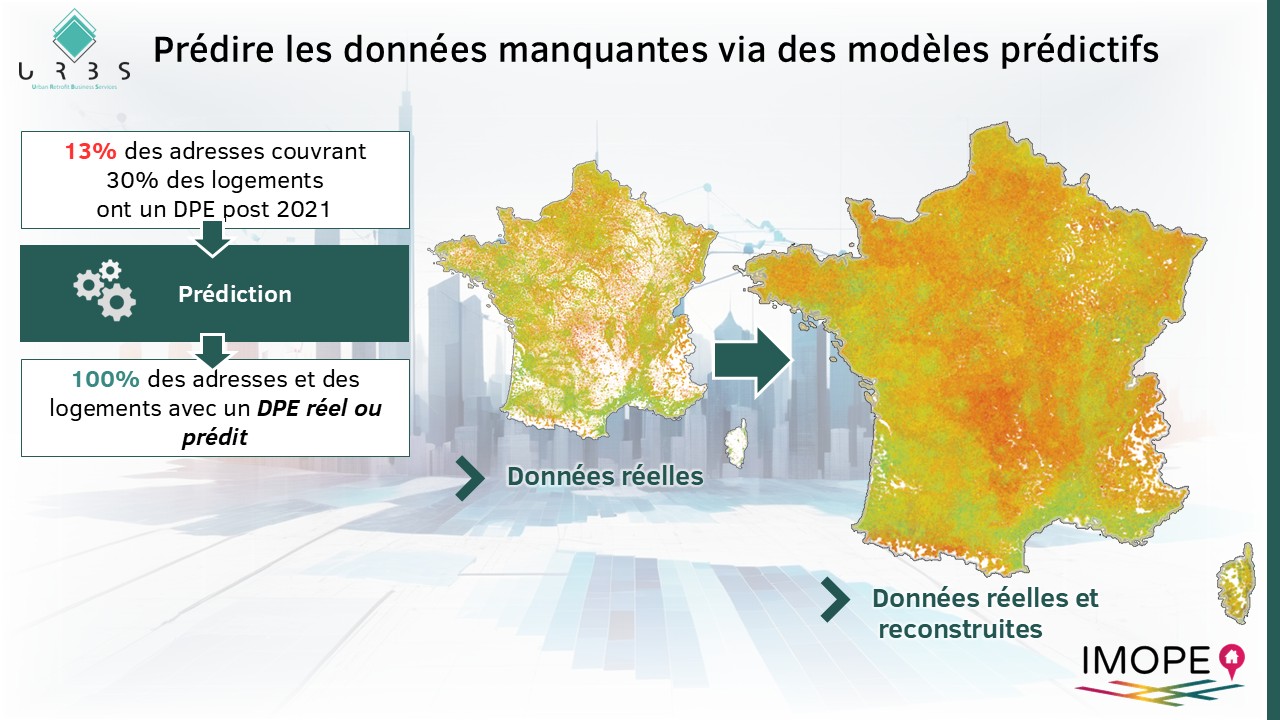
Une approche qui s’appuie sur des travaux validés et publiés**
Notre approche se base sur une démarche qui se veut intègre et robuste et qui a fait l’objet d’une validation par les pairs. Elle s’appuie sur un programme de recherche et des travaux validés et publiés :
- Programme de recherche avec l’École des Mines de Saint-Etienne (Institut Mines Telecom) depuis 2016
- Publications scientifiques reconnues et évaluées par des pairs :
 Marc Grossouvre, Didier Rullière, Jonathan Villot. Enhancing buildings’ energy efficiency prediction through advanced data fusion and fuzzy classification. Energy and Buildings, 2024, 313, pp.114243.
Marc Grossouvre, Didier Rullière, Jonathan Villot. Enhancing buildings’ energy efficiency prediction through advanced data fusion and fuzzy classification. Energy and Buildings, 2024, 313, pp.114243.- Marc Grossouvre, Didier Rullière, Jonathan Villot. Predicting missing Energy Performance Certificates: Spatial interpolation of mixture distributions. Energy and IA, 2024, 16, pp.100339.
- Didier Rullière, Marc Grossouvre. A joint kriging model with application to constrained classification. Stat Comput 35 , 220 ,2025.
Méthodologie
Il existe trois grande familles de modèle pour prédire les DPE :
- les modèles physiques (e.g. méthode réglementaire 3CL) qui utilisent les caractéristiques physiques de bâtiments. Ces modèles sont difficilement généralisables car ils nécessitent des données précises récoltées sur le terrain. Il est donc difficile de les généraliser à grande échelle à tout le parc de logements.
- les modèles hybrides qui proposent une approche simplifiée du modèle physique nécessitant moins de données d’entrée. Ce type de modèle permet la simulation de scénario mais nécessite d’estimer de nombreuses données d’entrée entrainant une propagation des incertitudes.
- les modèles statistiques, modèle que l’on met en œuvre chez U.R.B.S., dans lequel on se base sur des algorithmes d’intelligence artificielle afin d’établir des liens statistiques entre les informations connus sur le bâtiment et son DPE. Dans ce type de modèle on valorise tout type d’information : aussi bien des informations techniques que géographique ou sociologique. Les attributs de la base IMOPE sont ici pleinement mobilisés. Dans ce type de modèle, il n’y a pas de données à estimer. L’inconvénient de ce type de modèle est que la simulation de scénario est difficile et qu’il nécessite un grand échantillon d’apprentissage. Cependant, la base des DPE réels étant suffisamment grande, cette dernière limite n’en est pas vraiment une.
Chez U.R.B.S., nous utilisons une combinaison de modèles de la famille des modèles statistique.
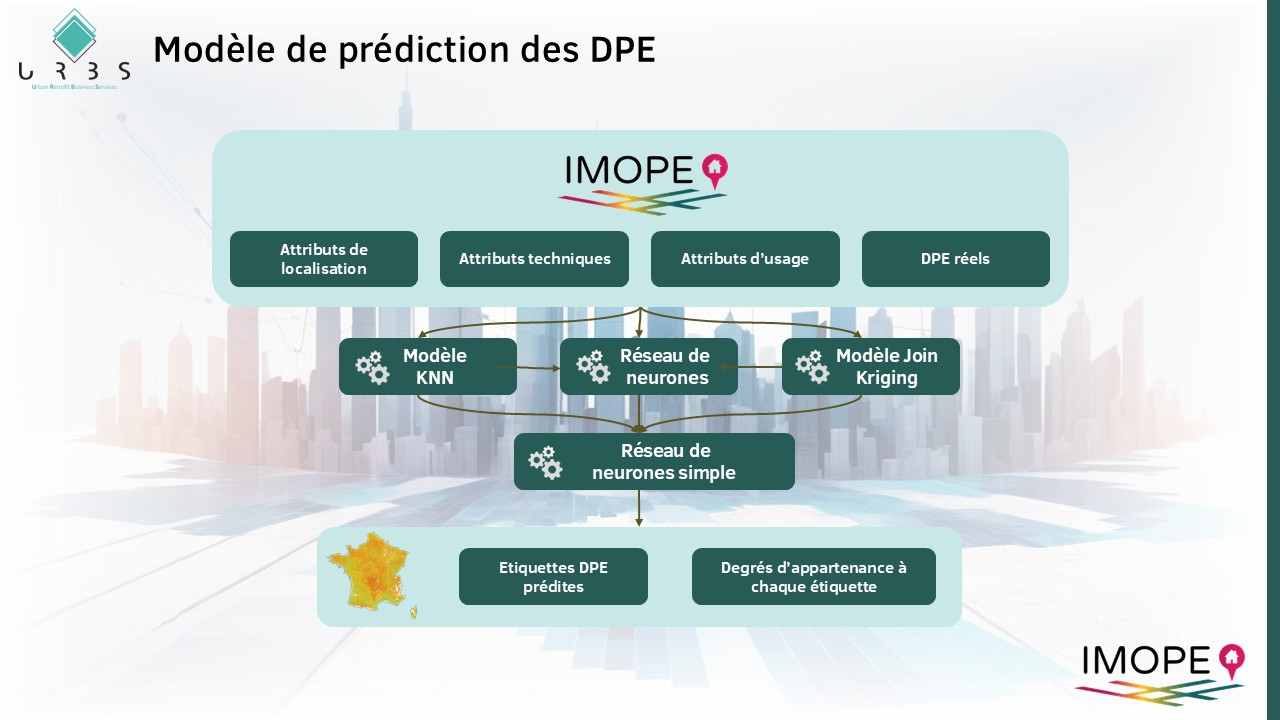
Modèle de prédiction des DPE
Ces modèles reposent sur les données réelles et en particulier un ensemble de variables caractéristiques des bâtiments parmi lesquelles :
- Des caractéristiques de localisation : altitude, latitude, longitude, …
- Des caractéristiques techniques du bâtiment : type de chauffage, source d’énergie, âge du bâtiment, matériaux des murs et du toit, état d’entretien et le niveau de confort, nombre d’étages, …
- Des caractéristiques d’usage : logement HLM, nombre de logements, la typologie d’occupation et de propriétaires, …
Chaque variable intervient dans les différents modèles avec un poids différent.
Nous utilisons une combinaison des trois modèles suivants :
- Modèle de type KNN (k plus proches voisins) : selon la proximité des différentes caractéristiques étudiées, on donne un poids à chacune des étiquettes DPE. Ce poids représente la proximité entre l’individu (ici un bâtiment) pour lequel on souhaite prédire l’étiquette) et les k plus proches voisins. Ce modèle prédit une probabilité d’appartenance aux 7 étiquettes DPE.
- Modèle « Nested Join Krieging ». il s’agit d’un algorithme de krigeage, c’est à dire qu’il adapte aux données un modèle linéaire sur les observations, et non pas sur les variables observées (régression linéaire). Sa particularité est de pouvoir prédire plusieurs variables en même temps, ici les degrés d’appartenance aux 7 étiquettes DPE. De plus, il permet de respecter 2 contraintes qui nous intéressent particulièrement : la somme des degrés d’appartenance pour une prédiction doit être égale à 1 et la distribution des degrés d’appartenance doit être la même que celle qu’on observe sur le parc de logements qui nous intéresse.
- Réseau de neurones : celui-ci alimenté par les mêmes variables que les deux premiers modèles et par leur résultats.
Une fois qu’on a les résultats des trois modèles obtenus, leurs prédictions servent de données d’entrée pour l’entraînement d’un second réseau de neurones simple à deux couches fully connected. La prédiction finale est la prédiction de ce réseau de neurones.
Pour aller plus loin :
![]() Regarder le webinaire consacré aux DPE sur Youtube
Regarder le webinaire consacré aux DPE sur Youtube
Fiabilité des prédictions
Niveau de fiabilité globale
![]() Les niveaux de fiabilité varient légèrement selon les territoires, puisque nos modèles s’adaptent aux spécificités régionales. Nous retrouvons en moyenne les résultats suivants (modèle 2026) :
Les niveaux de fiabilité varient légèrement selon les territoires, puisque nos modèles s’adaptent aux spécificités régionales. Nous retrouvons en moyenne les résultats suivants (modèle 2026) :
- 47% de fiabilité (+/- 0 étiquette)
- 85% de fiabilité (+/- 1 étiquette)
Ces chiffres correspondent à l’exactitude (accuracy) c’est à dire au taux global de bonnes prédictions.
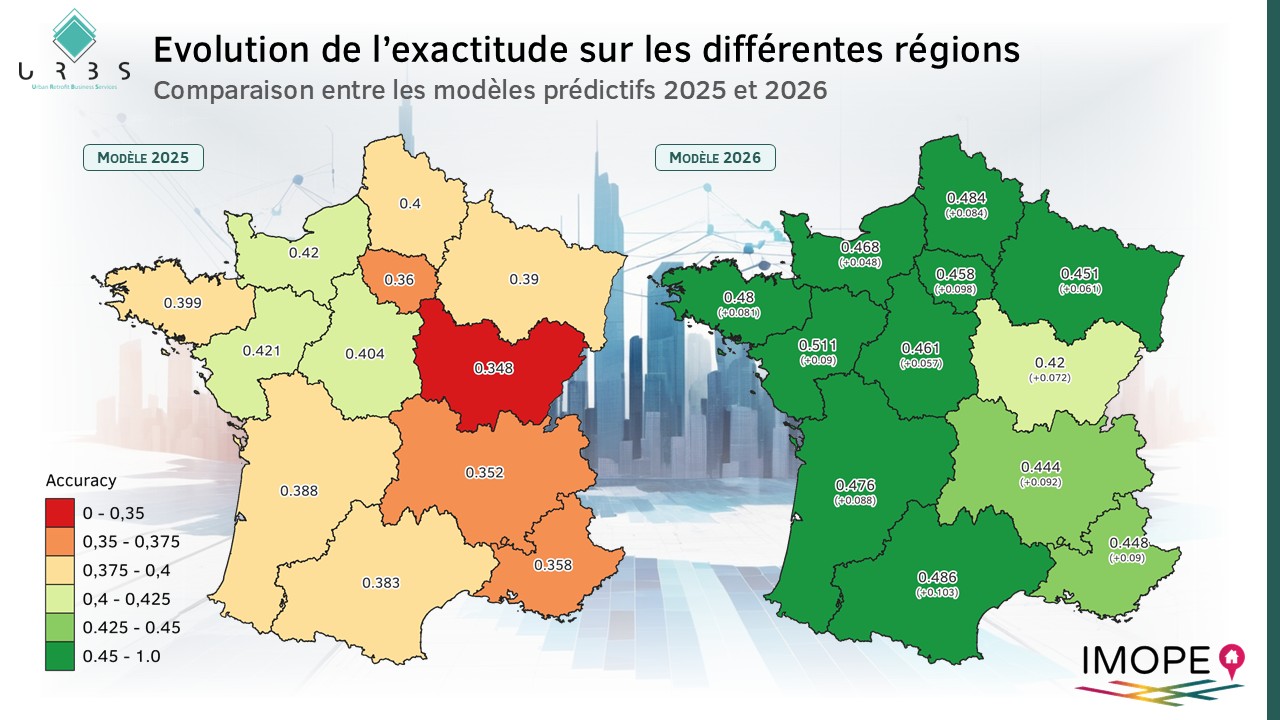
Evolution de la fiabilité du modèle
Depuis le premier modèle de prédiction des DPE réalisé en 2021, U.R.B.S. travaille de manière continue à l’amélioration de ses modèles prédictifs.
Le modèle 2026, marque un nouveau pallier de fiabilité. En effet, là où nous observions précédemment une fiabilité variable selon les régions, le nouveau modèle, basé sur l’agrégation des résultats de trois modèles différents, permet dans un même temps d’améliorer la fiabilité globale et de réduire les écarts de fiabilités des résultats aux échelles régionales.

Evolution des résultats des modèles de prédiction des DPE - région PACA
Performances nationales et comparaison
À l’échelle nationale notre modèle à les performances suivantes. Elles sont présentés ici en comparaison de celles obtenues par le CSTB. Notez que nos méthodologies sont assez différentes : le CSTB se base selon nos informations sur une méthode de prédiction physique simplifié tandis que nous nous basons sur un ensemble de méthodes géostatistiques. La comparaison est réalisée sur la base du millésime en vigueur au 21/04/2026
Sensibilité par étiquette
La sensibilité (recall) de A est le taux de A bien prédits par rapport à l’ensemble des vrais A. C’est ce que voit le prédicteur.
| Etiquette | URBS | CSTB | Différence entre URBS et CSTB |
|---|---|---|---|
| Recall A | 0.659 | 0.200 | + 0.459 |
| Recall B | 0.182 | 0.185 | - 0.003 |
| Recall C | 0.546 | 0.685 | - 0.139 |
| Recall D | 0.638 | 0.483 | + 0.155 |
| Recall E | 0.247 | 0.321 | - 0.074 |
| Recall F | 0.222 | 0.111 | + 0.111 |
| Recall G | 0.272 | 0.229 | + 0.043 |
| Recall AB | 0.513 | 0.219 | + 0.294 |
| Recall CDE | 0.924 | 0.914 | + 0.010 |
| Recall FG | 0.394 | 0.299 | + 0.095 |
Pour URBS, les chiffres présentés correspondent aux seules prédictions.
La sensibilité montre l’effort d’URBS pour mieux prédire les étiquettes extrêmes. Celles-ci sont particulièrement importantes notamment pour l’identification des passoires thermiques.
On remarque que les prédictions sur les groupes d’étiquettes AB et FG sont particulièrement performantes chez URBS. Ce point est plutôt important car pour l’amélioration des performances du parc bâti le focus se fait en priorité sur les bâtiments les moins performants c’est à dire ceux ayant une étiquette F ou G.
Précision
La précision (precision) de A est le taux de A bien prédits par rapport à l’ensemble des A prédits. C’est ce que voit l’utilisateur.
| Etiquette | URBS | CSTB | Différence entre URBS et CSTB |
|---|---|---|---|
| Precision A | 0.679 | 0.250 | + 0.439 |
| Precision B | 0.436 | 0.250 | + 0.186 |
| Precision C | 0.543 | 0.565 | - 0.022 |
| Precision D | 0.453 | 0.459 | - 0.006 |
| Precision E | 0.366 | 0.410 | - 0.044 |
| Precision F | 0.327 | 0.205 | + 0.122 |
| Precision G | 0.365 | 0.160 | + 0.205 |
| Precision AB | 0.755 | 0.292 | + 0.663 |
| Precision CDE | 0.843 | 0.887 | - 0.044 |
| Precision FG | 0.560 | 0.360 | + 0.200 |
Du point de vue utilisateur, URBS surperforme aussi pour les étiquettes A, B, F, G et pour le groupes AB et FG.
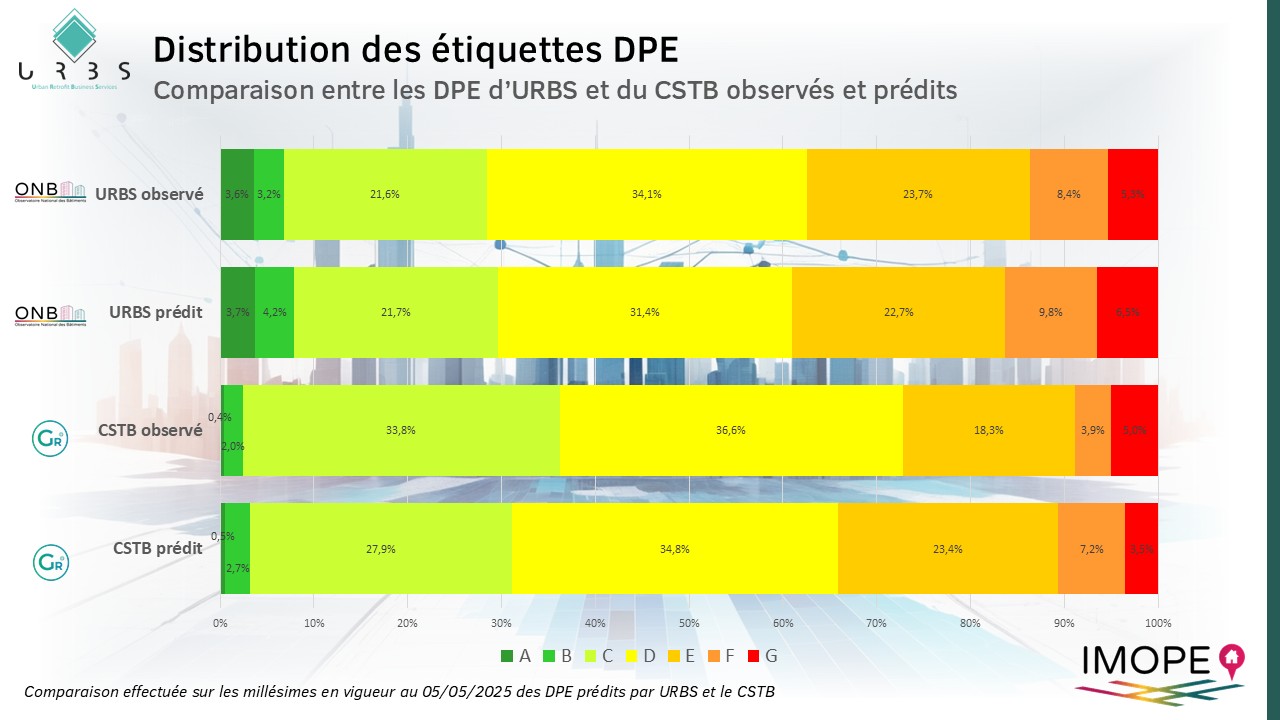
Distribution des DPE
Nous avons pu réaliser une comparaison à l’échelle nationale entre les prédictions réalisées par le CSTB et celles réalisées par URBS. Notez que les données publiées par le CSTB sont sous forme de pourcentage ce qui rend cette comparaison peu précise. À l’échelle France, la distribution que nous obtenons chez URBS nous semble plus réaliste tant dans les DPE prédits que dans ceux observés en particulier sur les classes extrêmes (A et B et dans une moindre mesure F et G).
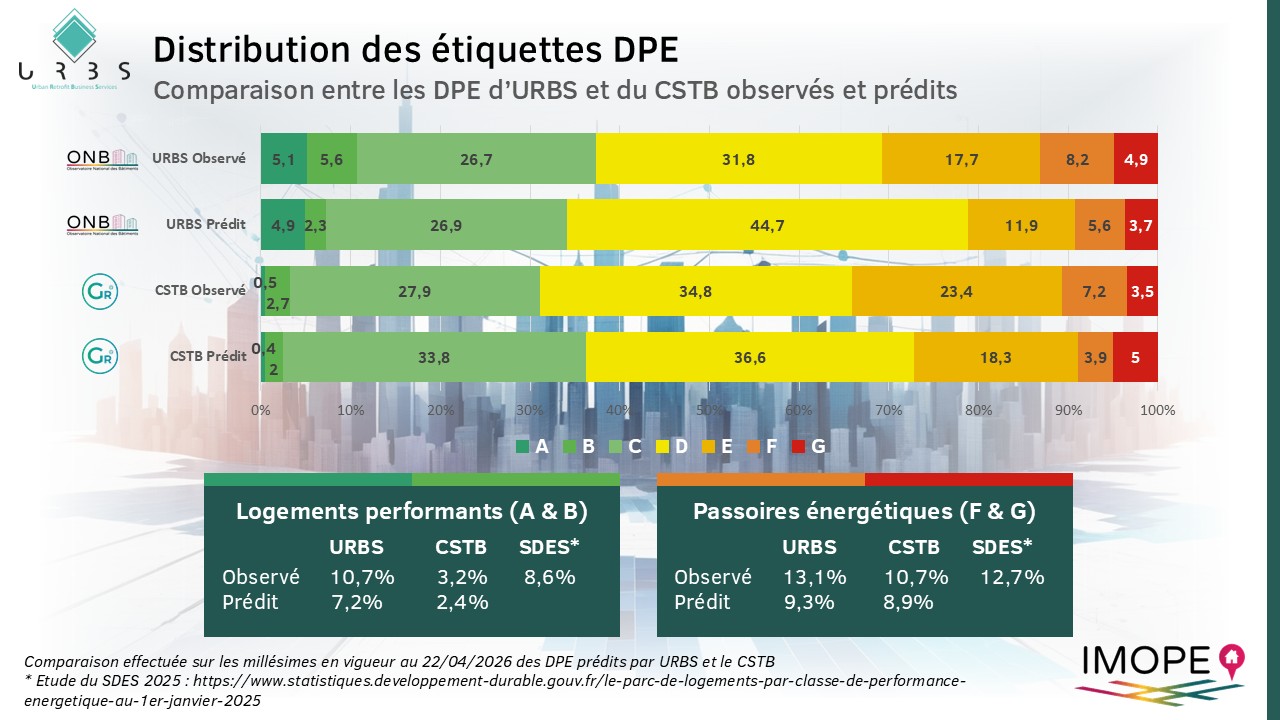
En particulier, les distributions obtenues par URBS sur les DPE observés des logements performants (étiquettes A & B) et des passoires énergétique (étiquettes F & G) sont plus proches des observations réalisées par le SDES début 2025 dans son étude des performances énergétiques du parc de logement.
Pour aller plus loin
Nos algorithmes ne se limitent pas à prédire les DPE : ils reconstruisent également les sources d’énergie et les types de chauffage des bâtiments non diagnostiqués (90% des adresses avec des données manquantes), offrant ainsi une visibilité complète sur l’ensemble du parc immobilier français (99-100% d’adresses qualifiées).
 Variable(s)
Variable(s)
Les attributs suivants sont disponibles dans la table adresse. Vous pouvez consulter la liste des attributs disponibles dans les autres table en consultant la liste des attributs dans la documentation d’IMOPE
inertie |
|
|---|---|
| Définition : Classe d’inertie du bâtiment | |
| Taux de complétude : 14.44% des adresses et 17.5% des adresses avec logement d’habitation | |
| Catégorie : DPE | Disponibilité : Open Data |
| Unité : | Fiabilité : |
| Millésime : 2026-04-17 | Source : Diagnostic de Performance Energetique 2025 - ADEME |
dpe |
|
|---|---|
| Définition : Etiquette énergie provenant du DPE le plus récent à l’adresse | |
| Taux de complétude : 15.1% des adresses et 18.23% des adresses avec logement d’habitation | |
| Catégorie : DPE | Disponibilité : Open Data |
| Unité : | Fiabilité : |
| Millésime : 2026-04-17 | Source : Diagnostic de Performance Energetique 2025 - ADEME |
energieecs |
|
|---|---|
| Définition : Source d’énergie pour l’eau chaude sanitaire provenant de données réelles | |
| Taux de complétude : 14.08% des adresses et 17.08% des adresses avec logement d’habitation | |
| Catégorie : DPE | Disponibilité : Open Data |
| Unité : | Fiabilité : |
| Millésime : 2026-04-17 | Source : Diagnostic de Performance Energetique 2025 - ADEME |
ndpeurbs |
|
|---|---|
| Définition : Valeur de consommation en énergie primaire issue du DPE le plus récent réalisé à l’adresse, sinon, la valeur est prédite par un modèle prédictif | |
| Taux de complétude : 76.13% des adresses et 100% des adresses avec logement d’habitation | |
| Catégorie : DPE | Disponibilité : |
| Unité : kWhep/m²/an | Fiabilité : |
| Millésime : 2026-04-17 | Source : Algorithme KNN de reconstruction des étiquettes énergie-climat manquantes 2026 - U.R.B.S |
numero_dpe |
|
|---|---|
| Définition : | |
| Taux de complétude : 15.1% des adresses et 18.23% des adresses avec logement d’habitation | |
| Catégorie : DPE | Disponibilité : |
| Unité : | Fiabilité : |
| Millésime : 2026-04-17 | Source : Diagnostic de Performance Energetique 2025 - ADEME |
ndpe |
|
|---|---|
| Définition : Valeur de consommation en énergie primaire issue du DPE le plus récent réalisé à l’adresse | |
| Taux de complétude : 15.1% des adresses et 18.23% des adresses avec logement d’habitation | |
| Catégorie : DPE | Disponibilité : Open Data |
| Unité : kWhep/m²/an | Fiabilité : |
| Millésime : 2026-04-17 | Source : Diagnostic de Performance Energetique 2025 - ADEME |
dpeurbs |
|
|---|---|
| Définition : Etiquette énergie provenant du DPE le plus récent à l’adresse, sinon l’étiquette est issue de modèles prédictifs | |
| Taux de complétude : 76.13% des adresses et 100% des adresses avec logement d’habitation | |
| Catégorie : DPE | Disponibilité : |
| Unité : | Fiabilité : |
| Millésime : 2026-04-17 | Source : Algorithme KNN de reconstruction des étiquettes énergie-climat manquantes 2026 - U.R.B.S |
ubat |
|
|---|---|
| Définition : U synthèse du bâtiment qui exprime les déperditions globales par m² de surface habitable. Cet indicateur permet d’apprécier la performance de l’isolation du logement dans sa globalité. | |
| Taux de complétude : 15.1% des adresses et 18.23% des adresses avec logement d’habitation | |
| Catégorie : DPE | Disponibilité : Open Data |
| Unité : | Fiabilité : |
| Millésime : 2026-04-17 | Source : Diagnostic de Performance Energetique 2025 - ADEME |
typeecs |
|
|---|---|
| Définition : Type de système de l’eau chaude sanitaire issu de données réelles | |
| Taux de complétude : 14.09% des adresses et 17.08% des adresses avec logement d’habitation | |
| Catégorie : DPE | Disponibilité : Open Data |
| Unité : | Fiabilité : |
| Millésime : 2026-04-17 | Source : Diagnostic de Performance Energetique 2025 - ADEME |
date_dpe |
|
|---|---|
| Définition : Date d’établissement du dernier DPE | |
| Taux de complétude : 15.1% des adresses et 18.23% des adresses avec logement d’habitation | |
| Catégorie : DPE | Disponibilité : |
| Unité : | Fiabilité : |
| Millésime : 2026-04-17 | Source : Diagnostic de Performance Energetique 2025 - ADEME |
Dernière mise à jour des métadonnées : 2026-04-24 11:32:39
 Disponibilité dans les outils
Disponibilité dans les outils
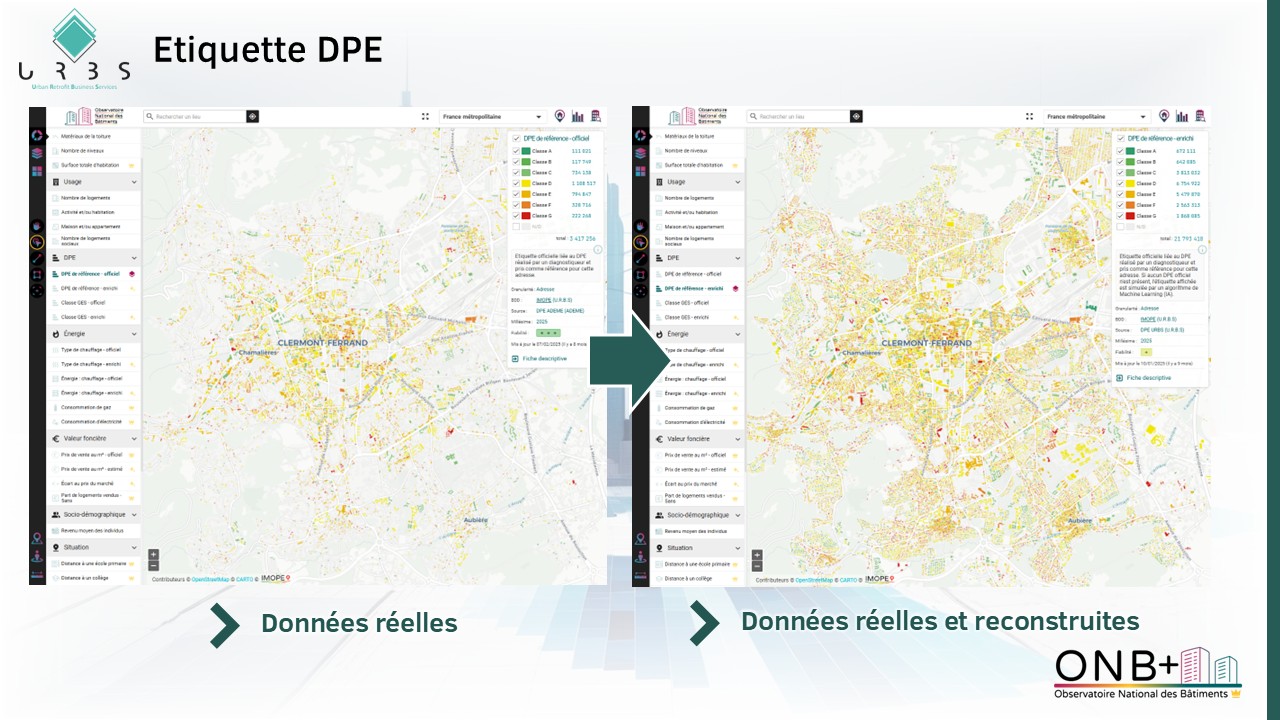
Les données réelles relatives aux DPE sont disponibles gratuitement pour tous dans l’ONB. Les données prédites ainsi que l’historique des DPE nécessitent une licence. Le DPE de référence est disponible dans l’ONB dans tous les outils : cartographie, tableaux de bord et outil de ciblage et de prospection.
 Cas d’usage
Cas d’usage
Les DPE réels et prédits sont mobilisé dans le domaine de l’amélioration des performance énergétique des bâtiments. Plusieurs cas d’usage sont documentés sur le forum :
- Intégration des DPE prédits au sein des outils métier - Métropole d’Aix-Marseille Provence
- La performance énergétique du parc résidentiel privé - Communauté urbaine Le Havre Seine Métropole
- Repérer les ménages potentiellement en situation de précarité énergétique
- Repérer les logements potentiellement interdits à la location dans moins de 10 ans
- La performance énergétique des logements appartenant aux communes
- Identifier le potentiel de décarbonation des sources de chauffage
- Un tiers des logements interdits à la location dans moins de 10 ans ? - URBS
![]() Votre contribution est la bienvenue pour compléter cette section ! N’hésitez pas à partager vos cas d’usage en réponse à ce message.
Votre contribution est la bienvenue pour compléter cette section ! N’hésitez pas à partager vos cas d’usage en réponse à ce message.
Source(s)
- Documentation détaillée des DPE sur le site de l’ADEME
- Marc Grossouvre, Didier Rullière, Jonathan Villot. Enhancing buildings’ energy efficiency prediction through advanced data fusion and fuzzy classification. Energy and Buildings, 2024, 313, pp.114243.
- Marc Grossouvre, Didier Rullière, Jonathan Villot. Predicting missing Energy Performance Certificates: Spatial interpolation of mixture distributions. Energy and IA, 2024, 16, pp.100339.
- SDES, 2025. Le parc de logements par classe de performance énéergétique au 1er janvier 2025
 Regarder sur Youtube le webinaire consacré aux DPE
Regarder sur Youtube le webinaire consacré aux DPE
 Foire aux questions
Foire aux questions
Généralités
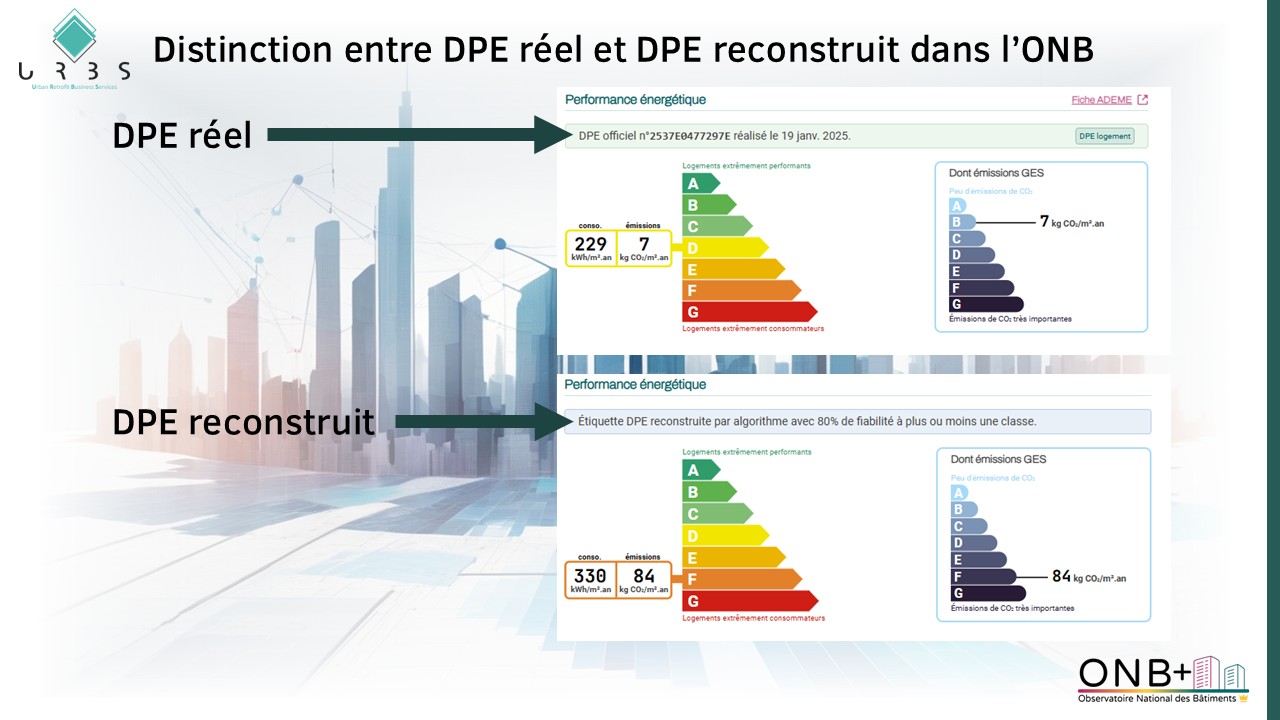
Quelle différence entre DPE réel et DPE prédit ?
![]() Réponse, en bref
Réponse, en bref
L’indicateur « DPE réel » est issue de la base de données des DPE (Diagnostics de Performance Energétique) de l’ADEME. Il s’agit du DPE réellement établi à ce jour sur le bâtiment. Cela concerne uniquement les DPE établis selon la méthode en vigueur depuis 2021. Les DPE établis avant cette date ne sont plus pris en compte car difficilement comparables à ceux établis depuis la réforme. Nous réfléchissons néanmoins à explorer les anciens DPE afin de récupérer d’autres informations lesquelles peuvent permettre de compléter la connaissance du bâti.
L’attribut « DPE prédit », disponible dans la version augmentée, est calculé par apprentissage machine, il s’agit ici d’un modèle mathématique prédictif qui apprend des données du bâtiment et des données DPE des bâtiments aux caractéristiques similaires. Cette prédiction est réalisée à partir de ce que nous connaissons du bâtiment : son degré de fiabilité est donc directement lié à la quantité et la qualité de données disponibles du ou des logements de l’adresse concernée, et de la complétude des données sur le territoire. La qualité varie donc fortement d’un bâtiment à l’autre et d’un territoire à l’autre. A noter que cet indicateur est purement informatif et n’a pas de caractère officiel (il ne peut pas être utilisé lors d’une transaction, vente ou location).
A noter que nous travaillons à l’amélioration continue de ces méthodes prédictives, notamment à travers un programme de R&D avec le soutien du Ministère de la Recherche et de l’Innovation, et de Mines St-Etienne
Qu'est ce que le DPE de référence ?
![]() Réponse, en bref Pour chaque adresse, nous faisons le choix d’un DPE de référence lorsqu’il en existe au moins un.
Réponse, en bref Pour chaque adresse, nous faisons le choix d’un DPE de référence lorsqu’il en existe au moins un.
Nous présentons pour chaque adresse possédant un DPE, un DPE dit de référence construit selon les règles suivantes :
- S’il existe un ou plusieurs DPE immeuble, nous présentons celui qui est le plus représenté ;
- Sinon, nous considérons l’étiquette la plus représentée parmi les DPE des logements de plus de 40 m².
Ce choix peut avoir un impact sur les autres indicateurs issus des DPE. Par exemple, pour les déperditions thermiques il est possible qu’elles apparaissent comme nulles dans le cas ou le DPE de référence est celui d’un logement situé au centre de l’immeuble (i.e. non en toiture ou en rez-de-chaussée). Dans cet exemple il n’y a pas de déchange thermique entre des zones chauffées dans le cadre du calcul du DPE.
Les DPE sont-ils uniquement prédit sur les bâtiments d'habitation ou également sur les bâtiments tertiaires ?
![]() Réponse, en bref
Réponse, en bref
Pour le moment, nous réalisons uniquement des prédictions pour les DPE logements. Les DPE tertiaires ne sont donc pas produits à ce stade.
Nos prédictions se basent sur les données existantes. Il est également important de noter que, pour le tertiaire, la base des DPE disponibles est significativement plus réduite que celle du résidentiel, ce qui peut limiter les possibilités de modélisation dans ce domaine.
Pour en savoir + : IMOPE tertiaire, base de données du parc bâti tertiaire
Dans le tableau de bord adresse, comment savoir si un DPE est réel ou prédit ?
![]() Réponse, en bref
Réponse, en bref
Cela est clairement notifié via un bandeau ou la mention « DPE réel » ou « DPE prédit ». À défaut vous pouvez cliquer sur les petits (i). Les métadonnées précisent alors la source et la méthode d’acquisition de l’attribut.
Dans les autres fonctionnalités (cartographie, tableau de bord territoire et outil de ciblage et de prospection), deux attributs existent : DPE de référence - officiel pour les DPE réels et « DPE de référence - enrichi » pour les DPE réels et simulés.
![]() Pour aller plus loin
Pour aller plus loin
Concernant les DPE réels, avons nous accès au DPE Collectif des copropriétés ?
![]() Réponse, en bref
Réponse, en bref
Oui, les DPE collectifs (DPE au bâtiment) sont bien en base. Si ce dernier est disponible il constitue alors le DPE de référence pour l’adresse considérée. Dans le cas où l’on en a plusieurs, on sélectionne le DPE immeuble le plus représenté. Cela est indiqué directement dans l’interface du tableau de bord adresse.
Si aucun DPE immeuble n’est présent le DPE de référence sera sélectionné parmi la liste des DPE au logement pour cette adresse : nous prenons alors le plus représenté parmi les logements de plus de 40m². Notons que via l’ONB+ vous disposez de l’historique des DPE à l’adresse et ce depuis l’application du nouvel arrête en 2021.
Traitement des DPE réels
Quels sont les limites des DPE réels ?
![]() Réponse, en bref
Réponse, en bref
La base des DPE de l’ADEME nécessite un travail de nettoyage, correction et géolocalisation des DPE notamment via l’adresse renseignée. Ce nettoyage fait, le DPE peut être croisé avec toutes les autres données de la base IMOPE. C’est ici la plus-value du travail réalisé par U.R.B.S et mis à disposition dans l’ONB.
L’interprétation de ces données doit être faite avec précaution. En effet, le DPE est obligatoire seulement pour une vente, une location ou à l’achèvement de toute nouvelle construction. Ainsi, tous les biens ne sont pas dotés d’un DPE. A ce titre, la base de données DPE ne couvre pas l’ensemble du parc immobilier et elle n’en est pas représentative.
Dans la base des DPE, comment traitez vous les DPE manifestement faux pour entrainer vos modèles?
![]() Réponse, en bref
Réponse, en bref
Tous les DPE ne sont pas sélectionnés pour alimenter le modèle. Notamment, les outliers sont écartés afin de limiter les biais dans les prédictions.
Cela dit, la notion de « manifestement faux » mériterait d’être discutée pour élaborer une méthode consensuelle et rigoureuse de détection. Il convient également de rappeler que les DPE sont opposables et, dès qu’ils sont remontés à l’ADEME, ils deviennent la valeur officielle de référence.
Pour les DPE « Faux » on voit bien des erreurs dans les données remontées (des sommes qui ne se font pas, des incohérences si on relance les calculs en sens inverse avec les mêmes paramètres d’entrées en respectant la méthode 3CL etc.)
![]() Réponse, en bref
Réponse, en bref
En effet, l’analyse de certains DPE peut révéler des incohérences. Le développement de modèles d’analyse spécifiques permettrait de détecter la « qualité » des DPE, ce qui serait bénéfique pour nos modèles. Cela permettrait notamment de sélectionner les DPE les plus qualitatifs, améliorant ainsi la fiabilité des prédictions.
Quelle est la fréquence de mise à jour des DPE réels ?
![]() Réponse, en bref
Réponse, en bref
Notre base de données DPE était jusqu’à présent mise à jour une fois par an au printemps. Elle intégrait donc les DPE extrait en début d’année (courant janvier ou février selon les millésimes).
Depuis mi-2025, nous les mettons à jour à une fréquence trimestrielle, afin de vous proposer des informations toujours plus actuelles. Ces mises à jours sont renseignées dans le Changelog.
A noter que ces durées s’expliquent par les traitements approfondis que nous appliquons aux données brutes de l’ADEME (fournisseur des DPE). En effet, leur qualité initiale nécessite des corrections et des enrichissements, notamment pour garantir une localisation précise des diagnostics.
Méthodologie de prédiction des DPE
Où pouvons nous trouver quelques détail sur la méthode d’IA utilisé ? notamment sur la précision des modèles ?
![]() Réponse, en bref
Réponse, en bref
Les algorithmes d’IA développés par U.R.B.S ont fait l’objet de publications scientifiques dans des articles « rankés » et de ce fait ont bénéficié d’une relecture/validation par les pairs. Tous les éléments sont disponibles dans ces articles.
Voici quelques références :
![]() Projet de recherche avec l’École des Mines de Saint-Étienne / thèse de Marc Grossouvre
Projet de recherche avec l’École des Mines de Saint-Étienne / thèse de Marc Grossouvre
![]() Article : Enhancing buildings’ energy efficiency prediction through advanced data fusion and fuzzy classification
Article : Enhancing buildings’ energy efficiency prediction through advanced data fusion and fuzzy classification
![]() Article : Predicting missing Energy Performance Certificates: Spatial interpolation of mixture distributions
Article : Predicting missing Energy Performance Certificates: Spatial interpolation of mixture distributions
Notons la pertinence de votre question, car sur les sujets IA, si la communication est omniprésente chez nos confères, les garanties scientifiques sont souvent édulcorées voire inventées : peu de transparence sur les éléments méthodologiques, peu d’informations sont mises à disposition publiquement par les acteurs producteurs de données prédites.
L’appariement à l’adresse des DPE est aussi lié à l’identifiant BAN directement disponible dans les fichiers XML envoyés à l’ADEME. Ces données ne sont pas exploitables ?
![]() Réponse, en bref
Réponse, en bref
En effet. Toutefois, à notre connaissance, les adresses des DPE dans la base ADEME ne font pas l’objet d’un nettoyage préalable. Cela peut donc impacter la qualité du lien avec la BAN.
C’est pourquoi nous n’utilisons pas directement le lien fourni par la BAN. Nous restructurons les adresses et régénérons un lien avec la BAN après un processus de standardisation et de redressement. Ce lien peut donc différer du lien initial.
Nos études comparatives montrent néanmoins une nette amélioration de la qualité et de la fiabilité des appariements grâce à notre processus en amont.
Dans votre méthode prédictive, vous n’avez pas accès à la consommation des logements qui permettrait d’être au plus juste? En effet, si un logement proche a fait l’objet d’un DPE récent avec une bonne valeur de DPE alors que le logement d’à côté est à l’abandon, on va l’estimer à bonne car le plus proche voisin est bon.
![]() Réponse, en bref
Réponse, en bref
Les données de consommations réelles ne sont malheureusement pas accessibles pour tous les bâtiments en France. Dans le secteur résidentiel, par exemple, il est nécessaire de disposer d’au moins 9 Points de Livraison (PDL) pour obtenir des données réelles de consommation. Par conséquent, seules les structures de logement collectif peuvent bénéficier d’un apprentissage basé sur ces données.
Par ailleurs, le concept de « plus proche voisin » dans le modèle ne repose pas uniquement sur une proximité géographique. Par exemple, si un bien est abandonné, il sera probablement classé comme vacant et/ou associé à un mauvais indice d’insalubrité. Le modèle est conçu pour détecter ces différences et ajuster les prédictions en conséquence.
Comment les rénovations énergétiques sont elles prises en compte ?
![]() Réponse, en bref
Réponse, en bref
À ce jour, il n’existe pas de base de données publiques recensant la réalisation de rénovations pour un logement, ni le détail de ces rénovations.
L’accès à ce type de données serait particulièrement pertinent, notamment pour améliorer l’efficacité et la précision de notre modèle prédictif.
Est ce que l’épaisseur des murs est prise en compte maintenant entre un murs de 10cm et un murs de 60 - 80 cm ?
![]() Réponse, en bref
Réponse, en bref
L’épaisseur des murs n’est pas une donnée disponible à grande échelle. Cependant, deux bâtiments qui présentent des similitudes importantes selon les variables mentionnées peuvent être considérés comme proches sur le plan structurel.
Fiabilité des DPE réels et des prédictions
Quelle est la fiabilité des DPE réels ?
![]() Réponse, en bref
Réponse, en bref
Concernant les DPE réels et contrairement à d’autres sources telles que les données du CEREMA (notamment les fichiers fonciers), il n’existe pas de fiabilité native.
Cependant, chez URBS, nous attribuons un haut niveau de fiabilité (+++) aux données issues des DPE. Cela s’explique par plusieurs raisons :
- Les DPE sont réalisés par des diagnostiqueurs certifiés,
- Ils sont (en principe) fondés sur des visites de terrain avec relevés,
- Ils sont opposables juridiquement,
- Ils sont regroupés par l’ADEME,
- Et ils sont utilisés au niveau national par différents ministères à des fins statistiques.
Ainsi, en tant que données officielles caractérisant la performance énergétique d’un bâtiment, leur opposabilité leur confère une valeur probante, tant pour l’acheteur que pour le vendeur. C’est pourquoi nous ne remettons pas en cause leur fiabilité en tant que donnée officielle faisant fois.
Par ailleurs, une étude menée en novembre 2024 par l’entreprise KRNO révèle que moins de 3 % des DPE présentent des irrégularités. Cela signifie que 97 % des diagnostics peuvent être considérés comme fiables.
Quelle est la fiabilité des DPE reconstruits ?
![]() Réponse, en bref
Réponse, en bref
La prédiction des DPE manquants issue de méthodes brevetées et validées par :
- un travail de R&D sur le sujet depuis 2017
- les paires scientifiques, via la publication d’articles de recherche
- le terrain et le déploiement en contexte opérationnel (amélioration continue des modèles en apprenant des données locales/terrain)
Les niveaux de fiabilité varient légèrement selon les territoires, puisque nos modèles s’adaptent aux spécificités régionales. Nous retrouvons en moyenne les résultats suivants :
- 78% de fiabilité (+/- 1 étiquette)
- 93% de fiabilité (+/- 2 étiquettes)
Dans votre modèle DPE IA, vous donnez toujours une note quelque soit votre taux de confiance, ou bien avez vous une catégorie « non prédis »? Donnez vous le taux de confiance pour une prédiction donnée?
![]() Réponse, en bref
Réponse, en bref
Le modèle prédit une probabilité d’appartenance à chacune des étiquettes (A à G). L’étiquette ayant la probabilité la plus élevée est considérée comme la plus représentative de l’adresse étudiée.
Pour chaque prédiction, nous fournissons également ce degré d’appartenance, permettant une meilleure compréhension de la précision et de la fiabilité des résultats.
Positionnement des données d’URBS par rapport à la concurrence
Comment les données DPE générées par l’IA se positionnent-elles par rapport aux autres offres commerciales qui émergent sur ce sujet ? Quels sont les avantages des données U.R.B.S par rapport aux concurrents ?
![]() Réponse, en bref
Réponse, en bref
Les confrères ne rendent pas toujours disponibles leurs résultats (ou ne le font que sur des périmètres très ciblés, ce qui fausse l’analyse à échelle nationale).
Récemment nous avons pu réaliser une comparaison entre les données produites par U.R.B.S et celles produites par le CSTB. Nos méthodologies sont assez différentes : le CSTB se base selon nos informations sur une méthode de prédiction physique simplifié tandis que nous nous basons sur une méthode géostatistique.
Nous avons pu réaliser une comparaison à l’échelle nationale entre les prédictions réalisées par le CSTB et celles réalisées par URBS. Notez que les données publiées par le CSTB sont sous forme de pourcentage ce qui rend cette comparaison peu précise. À l’échelle France, la distribution que nous obtenons chez URBS nous semble plus réaliste tant dans les DPE prédit que dans ceux observés en particulier sur les classes extrêmes (A et B et dans une moindre mesure F et G).
![]() Une suggestion ? Une question ? Nous sommes preneurs ! N’hésitez pas à partager vos remarques et à enrichir cette fiche descriptive avec vos questions en réponse à ce message.
Une suggestion ? Une question ? Nous sommes preneurs ! N’hésitez pas à partager vos remarques et à enrichir cette fiche descriptive avec vos questions en réponse à ce message.