![]() En résumé :
En résumé :
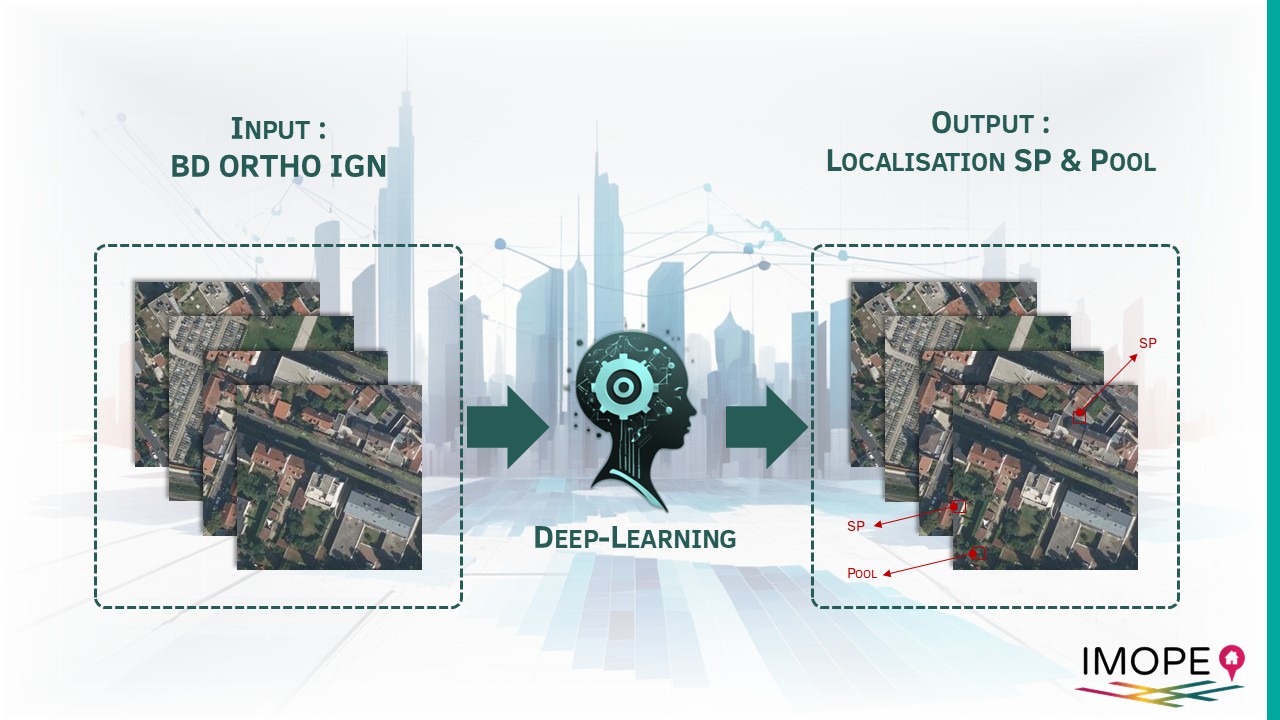
La présence de panneaux solaires et de piscines à l’adresse sont des données premium produites par U.R.B.S. Grâce à des techniques d’apprentissage profond (deep-learning) nous sommes en mesure d’identifier divers objets à partir d’images satellitaires. Aujourd’hui, nos modèles sont entraînés pour détecter les panneaux solaires et les piscines sur l’ensemble du territoires métropolitain. Les résultats sont imputés à l’adresses, mis à disposition dans la base IMOPE et restitués dans les tableaux bords adresse de l’ONB.
Méthodologie
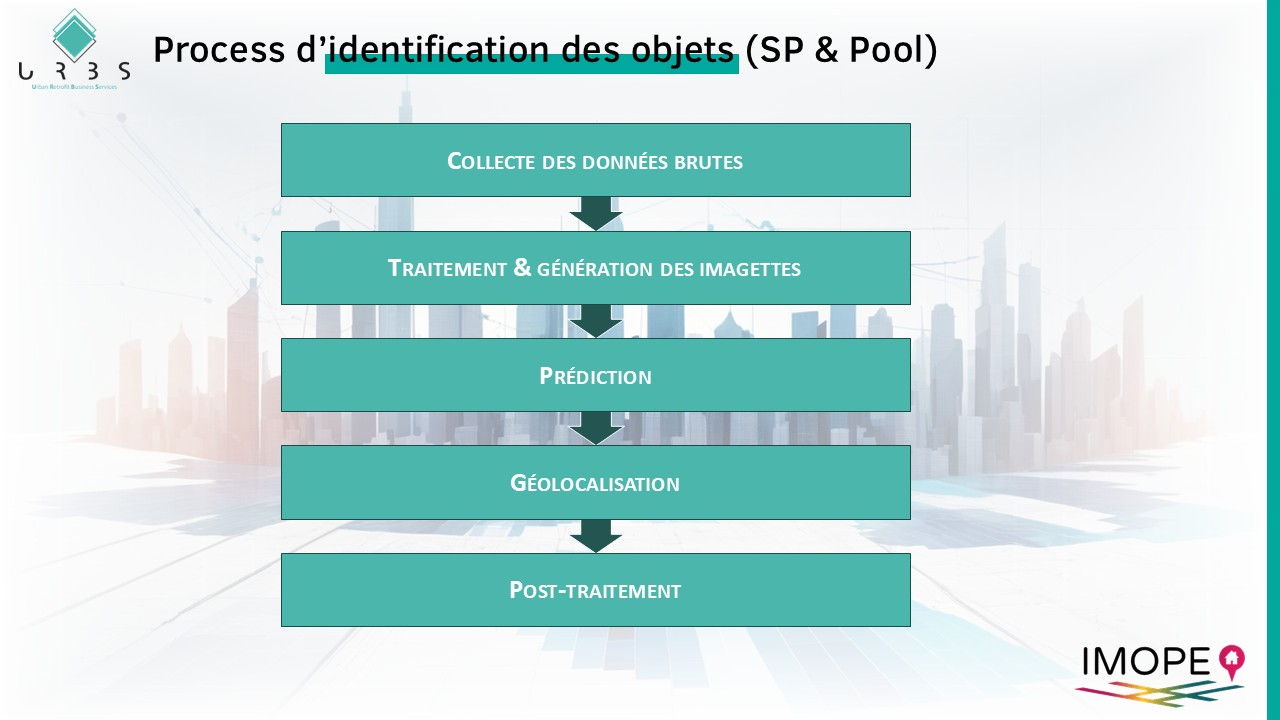
Afin de réaliser un tel repérage, le process mis en œuvre fait se succéder 5 étapes : collecte des données brutes, traitement et génération des imagettes, prédiction, géolocalisation et post-traitement.
Collecte des données brutes
La base d’images satellitaires utilisée dans notre modèle prédictif est la BD Ortho produite par l’IGN. Les données sont collectées sur la France entière à un instant t.
À noter que la BD Ortho est actualisée par département selon un cycle de 3 à 4 ans. Ainsi, pour le millésime produit en 2025, nous utilisons la BD Ortho 2024 dans laquelle 1/3 du territoire a été capturé en 2021, 1/3 en 2022 et 1/3 en 2023.
Traitement & génération des imagettes
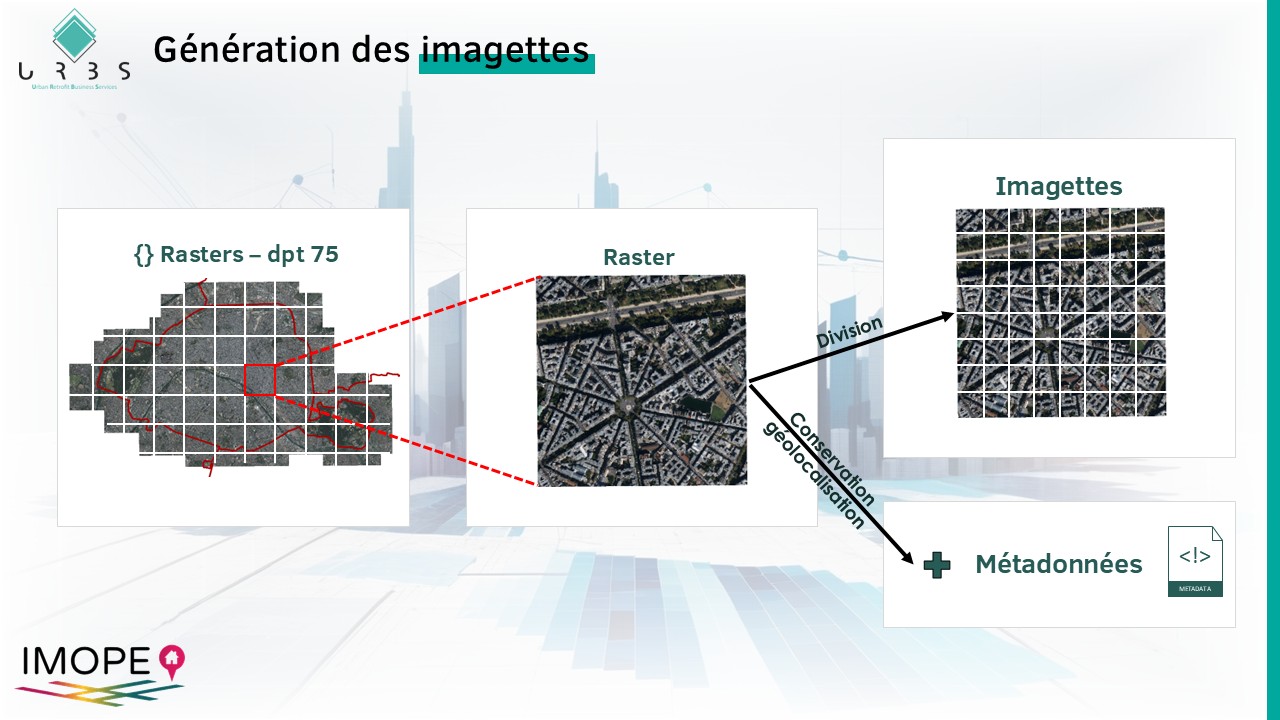
La première étape consiste à découper les rasters de la BD Ortho en images plus petites (imagettes) lesquelles seront ensuite analysées par nos modèles. Le traitement est effectué département par département. Pour chaque département ce traitement dure environ 10h, nécessite 300 à 400 go de stockage et abouti à la création d’environ 700 000 imagettes (pour un département de taille standard). En plus des imagettes, nous générons un fichiers permettant de conserver le lien entre imagette et géolocalisation. Ce lien sera ensuite mobilisé dans l’étape de « Géolocalisation » des objets identifiés en fin de process (étape 4).
Prédictions
Le process de prédiction se subdivise en trois étapes :
- La génération d’une base de données annotée (données d’apprentissage, de test et de validation)
- La conception et validation du modèle de prédiction
- Le process de prédiction en lui même
Génération de la base de données annotée
Avant de pouvoir concevoir le modèle en lui même, un prérequis est d’avoir une base de données d’apprentissage annotée suffisamment riche. Nous avons ainsi conçu une base d’apprentissage couvrant plusieurs départements et construite à partir de l’analyse d’environ 650 000 imagettes. In fine, cette base comprend un peu plus de 32 000 objets de type « panneaux solaires » et 30 000 objets de type « piscine ».
Conception et validation du modèle
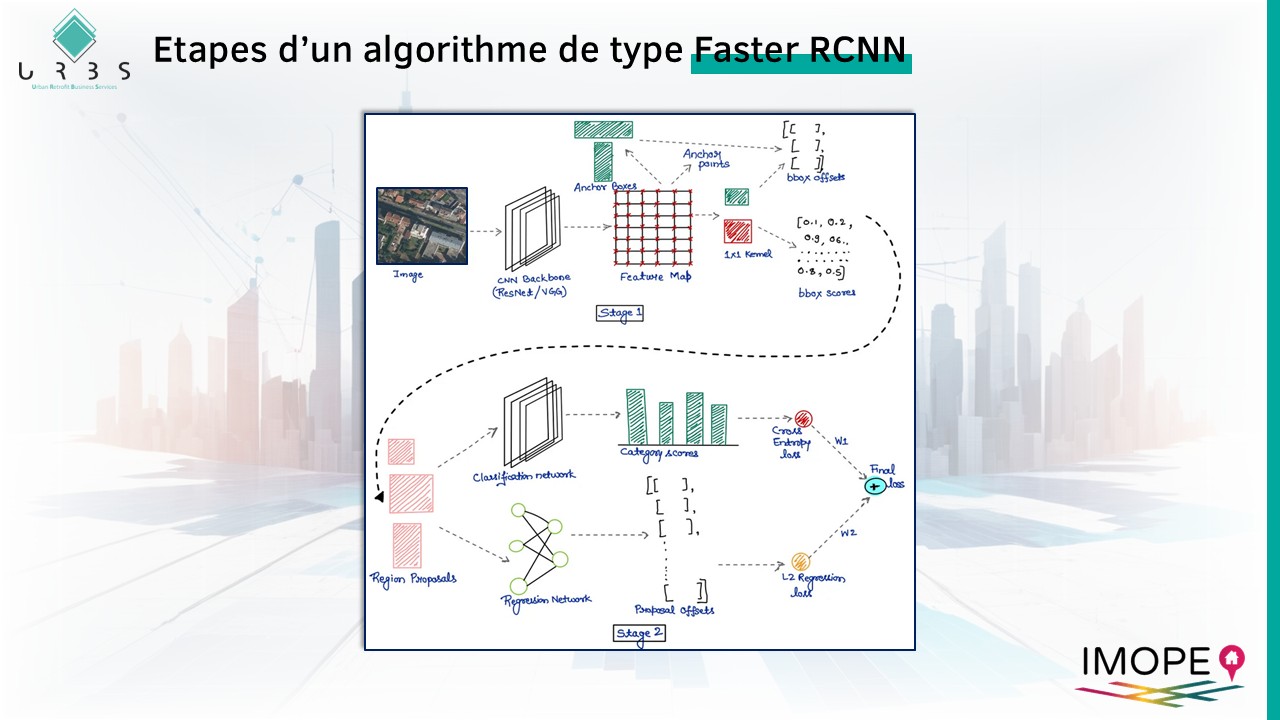
Le modèle choisi pour réaliser les prédictions à partir de la base d’apprentissage est un modèle de type « Faster RCNN ». Pour chaque type d’objet, on implémente, paramètre et entraine un modèle adapté à l’identification de ce type d’objet.
Dans chaque cas, un test et une validation sont réalisés sur une base de données de test (partition de la base de données d’apprentissage). Cela permet d’étudier les performance du modèle, la fiabilité de la détection et d’identifier d’éventuels problématiques de sous ou de sur apprentissage.
Le modèle présente la fiabilité suivante :
| Précision1 | Recall2 | |
|---|---|---|
| Identification des piscines | 81% | 89% |
| Identification des panneaux solaires | 74% | 67% |
1 La précision est le pourcentage de données correctes (True Positive) parmi l’ensemble des données détectées.
2 Le recall est le pourcentage de données correctement identifiées parmi celles qui auraient dû l’être.
Prédictions
Le processus de prédiction nécessite de 10 à 30h par département. L’output est un ensemble de deux fichiers JSON (un pour chaque type d’objets) de 200 à 400Mo par département comprenant les « bounding-box » des différents objets identifiés.
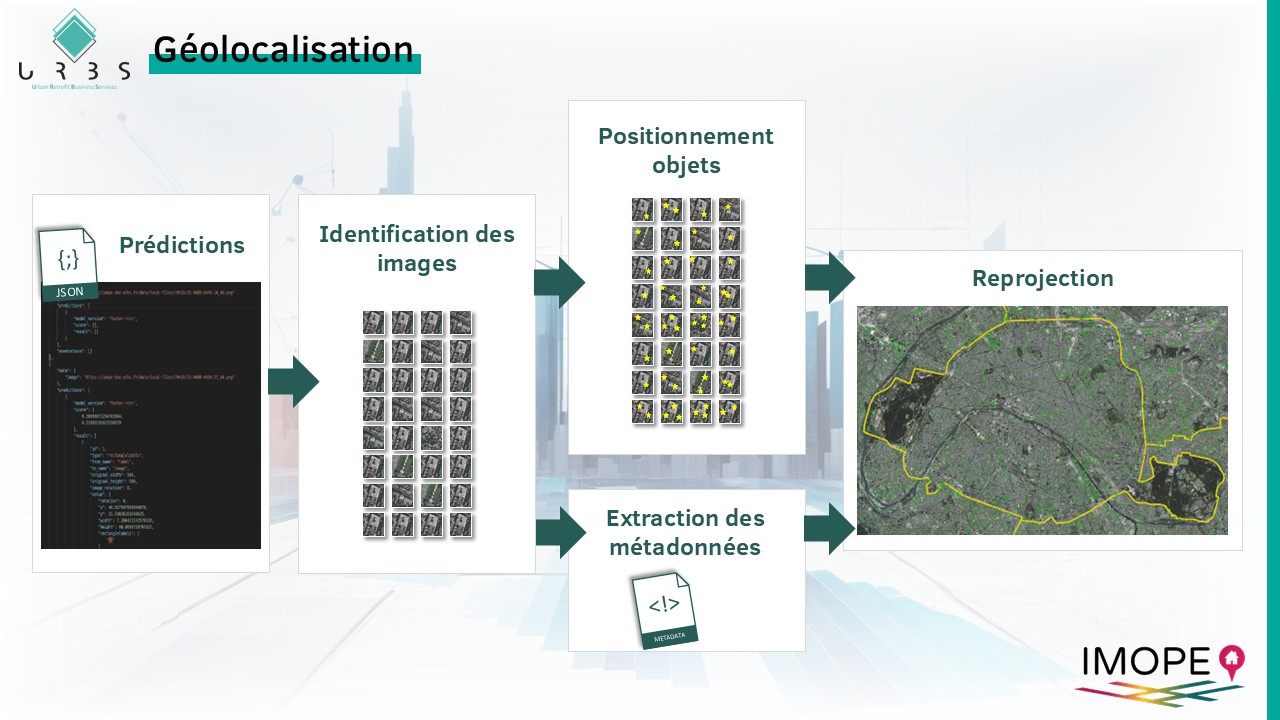
Géolocalisation
Les objets identifiés avec le modèle prédictif doivent ensuite être géolocalisés. Pour se faire, on mobilise les informations stockées à l’étape 2 lors du découpage en imagettes des rasters d’origine. De cette manière, chaque « bounding-box » identifiant un objet se voit dotée de coordonnées.
Post-traitement
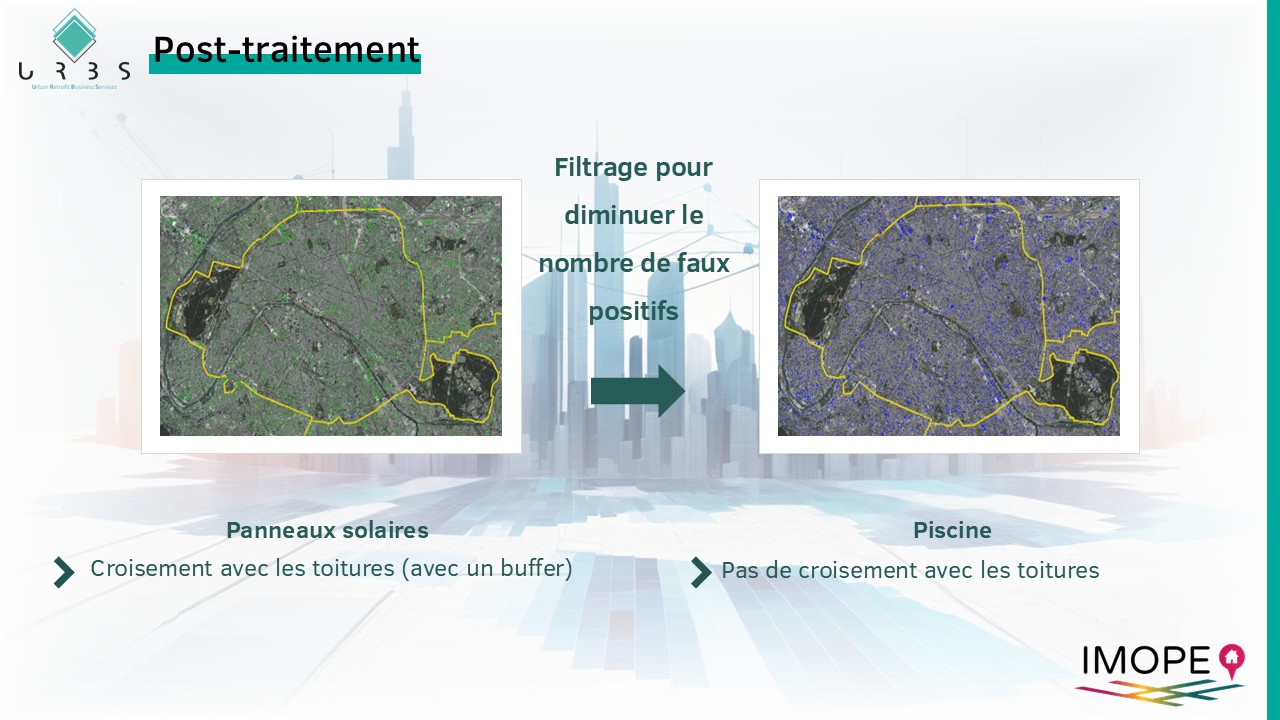
Malgré la fiabilité de notre algorithme, nous obtenons un certain nombre de faux positifs. Nous procédons à un post-traitement afin de nettoyer la base de données d’un certains nombre de cas problématiques.

Par exemple, pour les panneaux solaires, nous avons fait le choix de ne conserver que ceux construits sur des bâtiments. Nous comparons ainsi les résultats de nos algorithme avec une couche représentant le bâti. Pour les piscines au contraire, nous avons considéré qu’elles ne devait pas intersecter d’objets bâtis.
Enfin, par jointure spatiale avec le parcellaire, les données prédites sont associés à des identifiants de parcelles et d’adresses afin de restituer pour chaque adresse du territoire métropolitain une information sur la présence ou l’absence de panneaux solaires et de piscines.
Variable(s)
Les attributs suivants sont disponibles dans la table adresse. Vous pouvez consulter la liste des attributs disponibles dans les autres table en consultant la liste des attributs dans la documentation d’IMOPE
piscine |
|
|---|---|
| Définition : Présence de piscines | |
| Taux de complétude : 100% des adresses et 100% des adresses avec logement d’habitation | |
| Catégorie : Technique | Disponibilité : |
| Unité : | Fiabilité : |
| Millésime : 2026-04-17 | Source : Algorithme d’apprentissage profond pour l’identification des objets urbains 2025 - U.R.B.S |
panneau_solaire |
|
|---|---|
| Définition : Présence de panneaux solaires | |
| Taux de complétude : 100% des adresses et 100% des adresses avec logement d’habitation | |
| Catégorie : Technique | Disponibilité : |
| Unité : | Fiabilité : |
| Millésime : 2026-04-17 | Source : Algorithme d’apprentissage profond pour l’identification des objets urbains 2025 - U.R.B.S |
Dernière mise à jour des métadonnées : 2026-04-24 11:31:04
Disponibilité dans les outils
La présence de panneaux solaires et de piscines sont des attributs sous licence. Ils sont disponibles dans l’ONB dans les tableaux de bord et dans l’outil de ciblage et de prospection.
Cas d’usage
Outre l’investigation adresse par adresse, il est possible de mobiliser l’ensemble de la base de donnée IMOPE et ses différents identifiants pour synthétiser l’information à des échelles statistiques supérieures : iris, commune, EPCI, département … Dans l’exemple ci-dessous nous traitons les données imputées aux adresse pour ressortir par commune le pourcentage d’adresses ayant des panneaux solaires sur le département de l’Hérault (34).

![]() Votre contribution est la bienvenue pour compléter cette section ! N’hésitez pas à partager vos cas d’usage en réponse à ce message.
Votre contribution est la bienvenue pour compléter cette section ! N’hésitez pas à partager vos cas d’usage en réponse à ce message.
Source(s)
Foire aux questions
![]() Une suggestion ? Une question ? Nous sommes preneurs ! N’hésitez pas à partager vos remarques et à enrichir cette fiche descriptive avec vos questions en réponse à ce message.
Une suggestion ? Une question ? Nous sommes preneurs ! N’hésitez pas à partager vos remarques et à enrichir cette fiche descriptive avec vos questions en réponse à ce message.