La fiabilité des données rassemblées dans la base IMOPE est intrinsèquement liée à la qualité des données initiales. Cependant les traitements et correctifs opérés par U.R.B.S permettent un enrichissement conséquent des données sources.
En parallèle U.R.B.S. collabore étroitement avec les fournisseurs de ces données afin de remédier aux limites identifiées. À titre d’exemple, nous avons participé à la révision du modèle de données des diagnostics de performance énergétique, porté par l’ADEME.
La fiabilité des données dans les différentes version de l’ONB
Pour chaque indicateur disponible dans les différentes versions de l’ONB, il est possible d’accéder à la fiabilité des données :
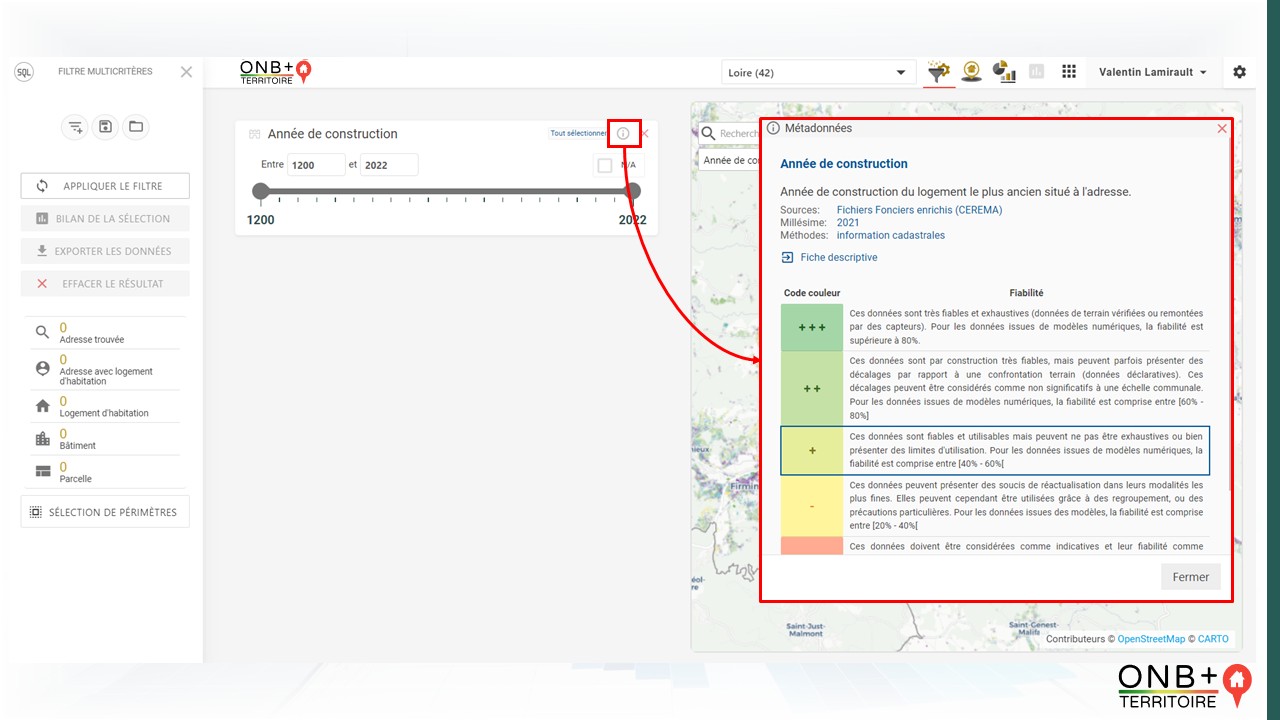
- Dans la cartographie, la fiabilité ainsi que les autres métadonnées sont disponibles dans l’encart contenant la légende. Le « i » permet d’accéder au détail.
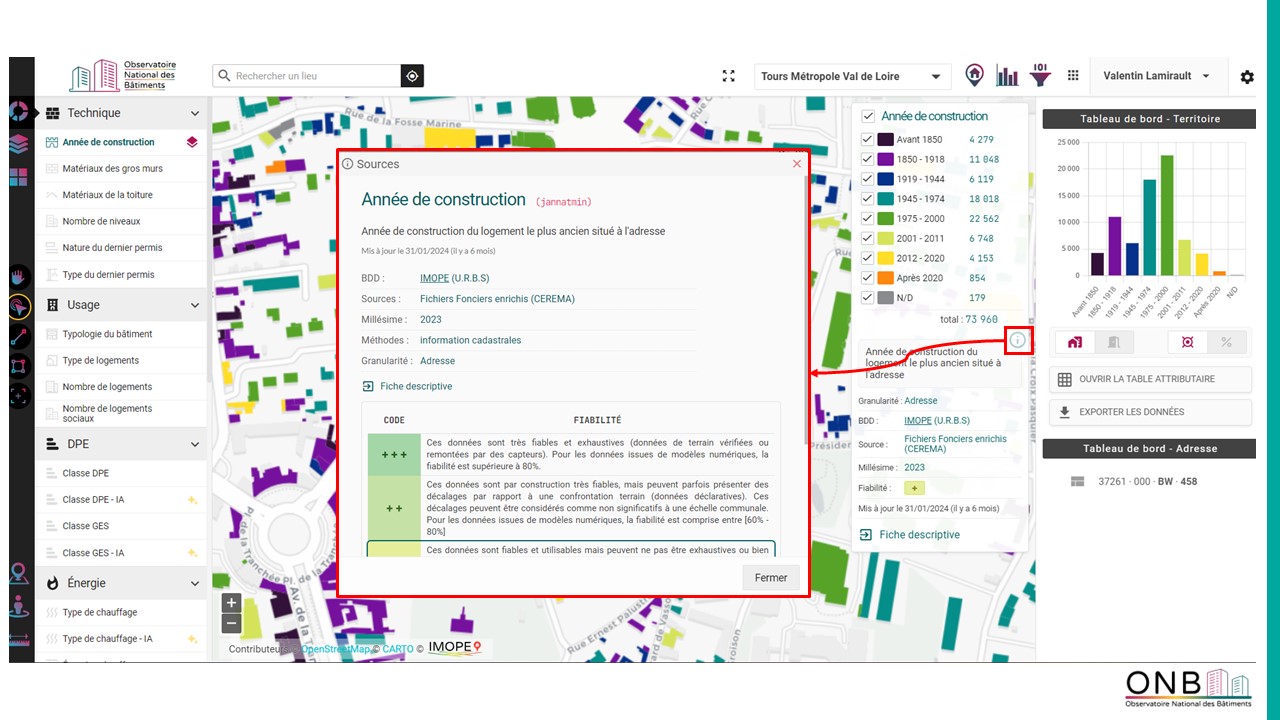
- Dans le tableau de bord territoire ou dans le tableau de bord adresse, la fiabilité de chaque attribut est accessible via les « i ».
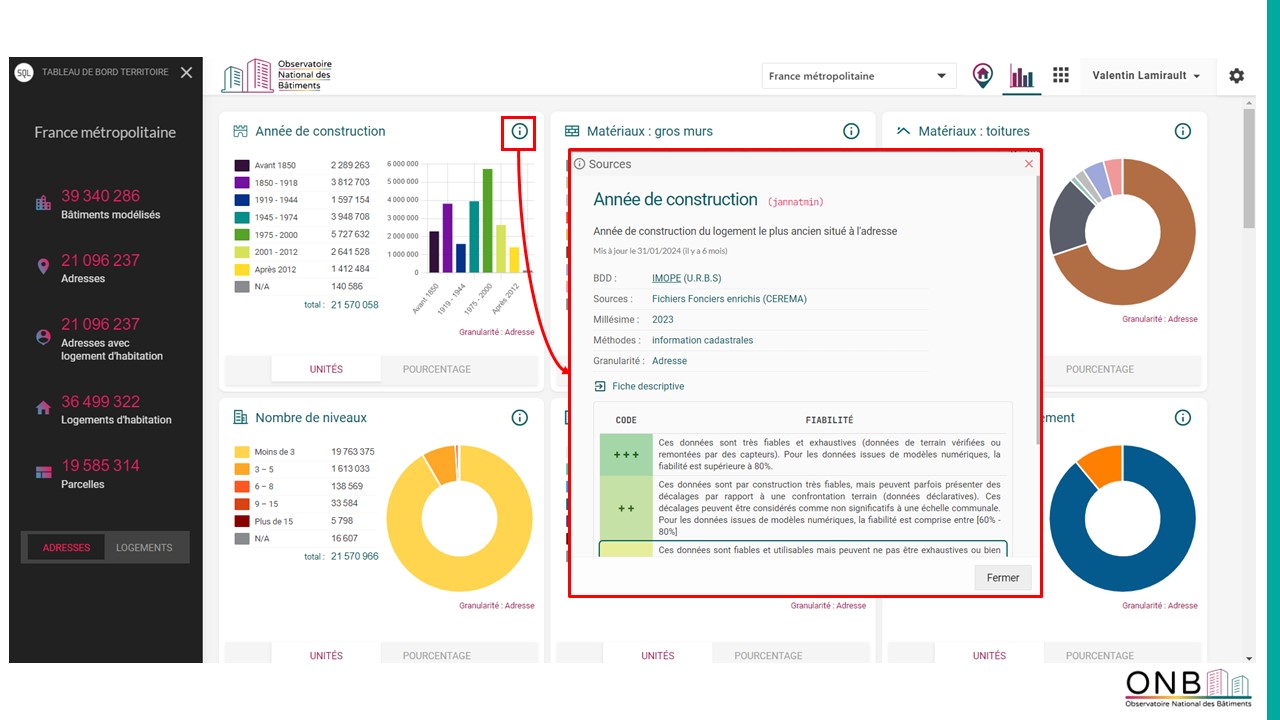
- Dans le filtre multicritère, une fois un attribut sélectionné comme filtre, sa fiabilité est accessible via le « i ».
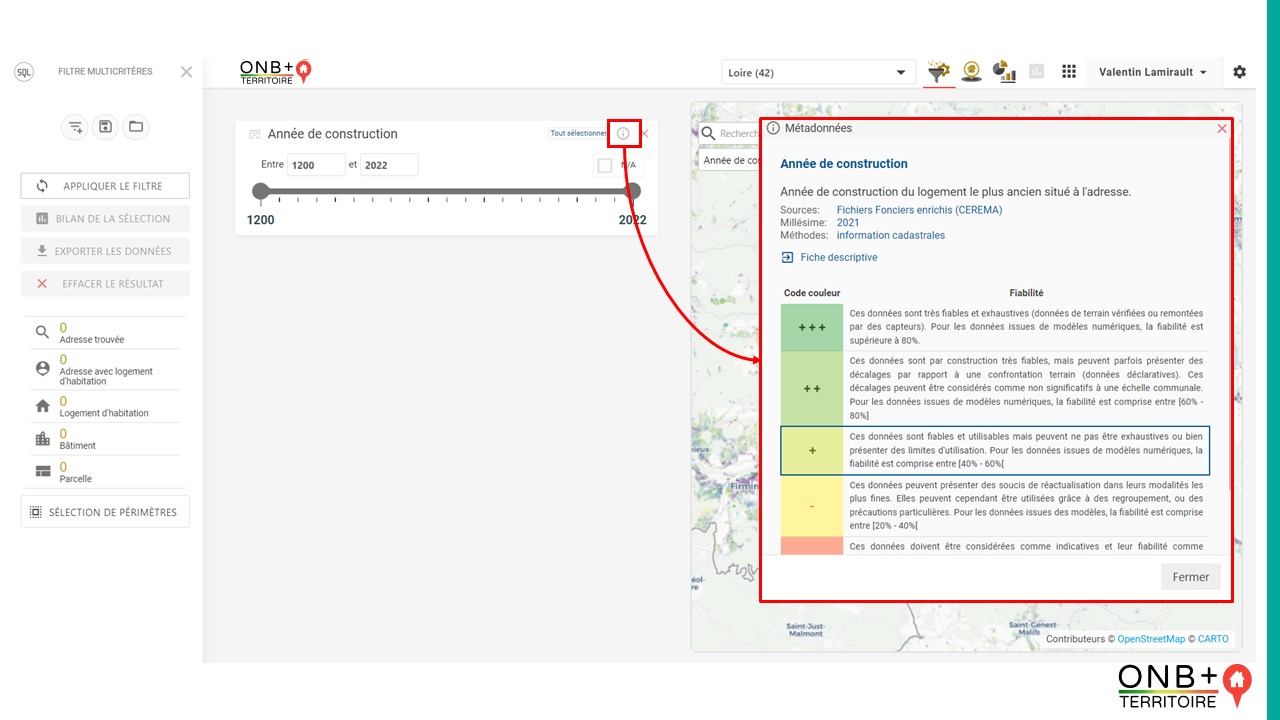
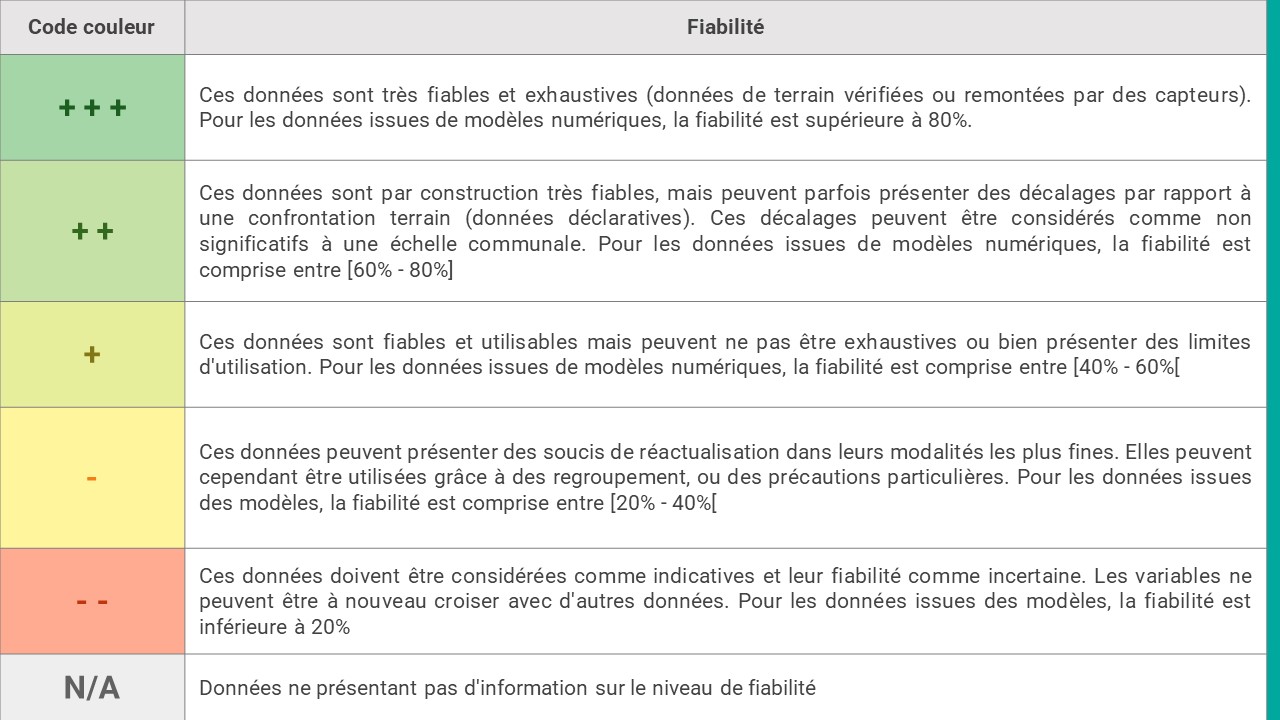
À chaque niveau de fiabilité est associé un code couleur selon la nomenclature suivante :
La fiabilité des données dans les géopackages
Dans les géopackages mis à disposition sur data.gouv ou livrés à nos partenaires, il est également possible de retrouver cette information pour chacun des attributs de la base IMOPE.
Les géopackages sont livrés avec une table « sources » laquelle contient un descriptif des sources de données. Au sein de cette table, la fiabilité des données est également renseignée.
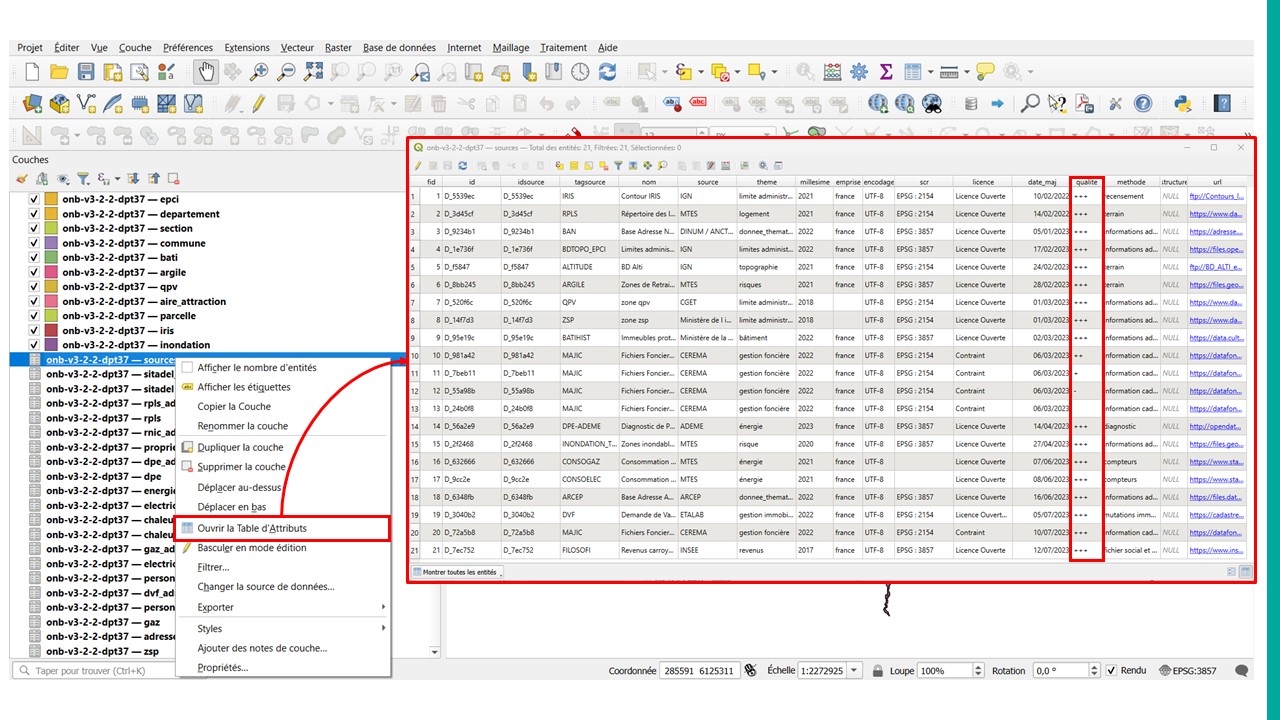
Si le géopackage est chargé dans QGIS, vous accéder au détail de la table "source en faisant un clic droit sur la couche et en cliquant sur « Ouvrir la Table d’Attributs ». Dans cette table, la colonne « qualité » renseigne sur la fiabilité de chacune des bases de données sources d’IMOPE selon la même nomenclature que dans nos applicatifs (cf. tableau précédent).
Foire aux questions
Fiabilité des données
Vos données sont-elles suffisamment fiables ?
![]() Réponse, en bref
Réponse, en bref
Les approches méthodologiques que nous proposons permettent de valider la pertinence, la fiabilité et la complétude des données déployées, d’une part grâce à nos travaux d’analyse de données et, d’autre part, confortés par les retours terrain des utilisateurs.
Cette qualité repose notamment sur 7 années de déploiement en contexte opérationnel, avec des retours quotidiens d’acteurs terrain, permettant une amélioration et consolidation continue de nos méthodologies.
Les niveaux de fiabilité et de complétude étant très hétérogènes selon le type des données, nous travaillons quotidiennement à analyser ces éléments. Dans l’attente de validation méthodologique, nous préférons la valeur N/A, qui n’induit pas une mauvaise qualité de la donnée.
Pourquoi un même indicateur a plusieurs niveaux de fiabilité ?
![]() Réponse, en bref
Réponse, en bref
Un même attribut peut être relié à différentes sources dont le niveau de fiabilité n’est pas le même. Ainsi cet indicateur aura plusieurs niveaux de fiabilité en fonction de la source considérée.
Certains bâtiments n’existent pas dans l'ONB ou n’existent plus dans la réalité ! Comment l’expliquer ?
![]() Réponse, en bref
Réponse, en bref
L’ONB regroupe à ce jour les données en open data de tous les bâtiments résidentiels de France métropolitaine. Les bâtiments à usage exclusivement tertiaire ne sont donc pas, à ce stade, mis à disposition dans l’ONB. Cette composante pourra néanmoins être intégrée dans les évolutions de l’outil.
D’autre part, nous utilisons pour la représentation cartographique les données issues du cadastre. L’absence d’un bâtiment signifie que ce dernier n’est pas encore présent dans les données cadastrales (alors qu’un fond de carte actualisé peut le présenter). Le cadastre étant mis à jour régulièrement, les prochains millésimes devraient intégrer ces bâtiments manquants et résoudre le problème. De la même manière un bâtiment récemment détruit pourra continuer à être affiché dans l’ONB jusqu’à la mise à jour de la donnée (pour rappel, la mise à jour est à minima annuelle).
Pourquoi les résultats d’une même recherche à quelques jours/semaines d’intervalles peuvent être différents ?
![]() Réponse, en bref
Réponse, en bref
Cela peut être dû aux mises à jour successives des bases de données. Nous essayons au maximum de stabiliser les bases et de maitriser l’intégration continue de nouvelles données ou de nouvelle version d’un jeu à une date fixée au préalable entre les parties intervenantes sur le projet. Cependant, certaines bases de données peuvent continuer à évoluer dans le cas de mises à jour importantes ou nécessaires pour le développement d’IMOPE.
D’autre part, une fois déployées sur l’ONB, certaines données peuvent continuer à évoluer par l’intermédiaire des remontées terrains. De ce fait, des écarts plus ou moins significatifs d’une semaine sur l’autre pourront être constatés au niveau de certains attributs.
Erreurs dans les données
Certaines données affichées ne sont pas exactes. Pourquoi ?
![]() Réponse, en bref
Réponse, en bref
En effet, certaines données peuvent être erronées ou inexactes en comparaison des informations recueillies sur le terrain. Ceci peut être expliqué par deux phénomènes :
- Le premier phénomène est lié au millésime de la donnée. En effet une base de données indiquant un millésime 2020 signifiera que la base a été formalisée durant l’année 2020. Nous nous attachons à afficher les données les plus récentes. Mais dans certains cas, les bases les plus récentes peuvent avoir quelques années d’ancienneté.
- Le second phénomène est lié à la fiabilité des données. Pour chacun des indicateurs présentés, le niveau de fiabilité de la donnée est affiché. Selon le niveau, les données peuvent présenter un décalage avec la réalité observée sur le terrain. Pour connaître précisément la fiabilité des données nous vous invitons à consulter la rubrique « Métadonnées » accessible depuis l’interface.
Pourquoi certains éléments chiffrés ne correspondent pas aux données statistiques d'autres bases connues ?
![]() Réponse, en bref
Réponse, en bref
Notre base de données regroupant des données multi-sources, il est important de préciser que toutes ces sources de données ont des méthodologies propres, qui peuvent possiblement diverger.
Exemple des données statistique de l’INSEE : l’INSEE est un organisme qui propose des données issues de la statistique publique. Ces données sont issues d’un échantillon extrapolé, suite aux enquêtes de recensement, et n’ont donc pas le même niveau de précision que certaines données contraintes collectées à une maille plus fine. Un retraitement de la donnée est effectué avant sa mise à disposition au public (anonymisation, etc.).
Les données proposées par U.R.B.S., quant à elles, sont des données qui n’ont pas subi de transformations majeures lorsque cela est possible (exemple : la donnée fiscale). Certaines données non exhaustives sur la France (ex : DPE) sont cependant retravaillées (méthodes prédictives) pour fournir à l’utilisateur une donnée plus complète sur le territoire. L’utilisateur est donc libre de proposer une analyse adaptée à ses besoins, sans perte d’information dû à une analyse statistique préalable.
Les décomptes de logements ou de surface ne correspondent pas à ce que je connais de l'adresse. Pourquoi ?
![]() Réponse, en bref
Réponse, en bref
Un élément courant que nous constatons est qu’un ensemble de logement perçus à une même unique adresse, peuvent être ventilés sur plusieurs adresses sur le plan fiscal.
Dans l’ONB, lorsque vous sélectionnez une parcelle, vous avez d’office accès à l’ensemble des adresses qui y sont rattachés. Lorsque vous faites la somme du nombre de logements ou des surfaces des différentes adresses vous retomberez souvent sur ce que vous connaissez du bâtiment.
Sur l’exemple ci-dessous, 3 adresses sont rattachées à une même parcelle et il est possible de naviguer entre elle grâce à la liste déroulante à gauche.
Peut-on corriger certaines données ?
![]() Réponse, en bref
Réponse, en bref
Dans l’ONB, il n’est pour le moment pas possible de contribuer à la base de données. URBS réfléchit activement à cette question afin de faire des usagers des contributeurs tant pour améliorer la donnée que pour la fiabiliser.
Dans l’ONB+ Territoire il est possible de renseigner des observations.
Années de construction
Je constate que l’année de construction renseignée pour une maison est 1980 alors qu’elle a été construite en 1733. Seule la grange située sur ce même terrain à été construite à cette date. D'où provient cette erreur ?
![]() Réponse, en bref
Réponse, en bref
Cette divergence est liée à un choix méthodologique que l’on réalise pour représenter les données dans l’ONB ou dans IMOPE. En effet, pour une même parcelle nous disposons de deux champs pour caractériser l’année de construction :
jannath_min: pour l’année de construction la plus ancienne.jannath_max: pour l’année de construction la plus récente.
Nous privilégions systématiquement l’année la plus ancienne car celle-ci est souvent la plus représentative. L’année de construction la plus récente correspond régulièrement à des ajouts ou modifications des bâtiments.
![]() Pour aller plus loin
Pour aller plus loin
![]() Fiche descriptive de l’attribut année de construction
Fiche descriptive de l’attribut année de construction
Je constate une erreur dans les données renseignées pour l'année de construction d'un bâtiment. Quelle peut être l'origine de cette erreur ?
![]() Réponse, en bref
Réponse, en bref
L’attribut « année de construction » est construit sur la base des données des Fichiers Fonciers ouverts.
En premier lieu, l’erreur peut venir de cette base source. En effet, cette donnée possède une fiabilité de niveau « + », c’est à dire que pour le CEREMA, « ces données sont considérées comme fiables et utilisables mais peuvent ne pas être exhaustives ou bien présenter des limites d’utilisation ».
En effet, il faut noter que la date de construction de l’habitat est « plus » fiable depuis 1971. Avant cela, les dates doivent être considérées comme approximatives car issues des déclaration des propriétaires lors de la mise à jour générale de cette donnée réalisée en 1970. À noter que la date « 0 » est l’équivalent de « non rempli » (laquelle est transformée en N/A dans IMOPE). L’erreur identifiée n’a pas été corrigée, car les mises à jour de ce champs sont rares voir non structurées
En second lieu, cette divergence peut être est liée à un choix méthodologique que l’on réalise pour représenter les données dans l’ONB ou dans IMOPE. En effet, pour une même parcelle nous disposons de deux champs pour caractériser l’année de construction :
jannath_min: pour l’année de construction la plus ancienne.jannath_max: pour l’année de construction la plus récente.
Nous privilégions systématiquement l’année la plus ancienne car celle-ci est souvent la plus représentative. L’année de construction la plus récente correspond régulièrement à des ajouts ou modifications des bâtiments.
![]() Pour aller plus loin
Pour aller plus loin
![]() Années de construction
Années de construction
INSEE et fichiers fonciers
Je constate des incohérences entre les données issues de l'INSEE et celles provenant des fichiers fonciers. Pourquoi ?
![]() Réponse, en bref
Réponse, en bref
Cela est tout à fait normal dans la mesure où ces deux jeux de données n’ont pas la même fréquence ni la même méthode de collecte.
Si les fichiers fonciers peuvent présenter des erreurs, ces données collectées par les services des impôts sont plus fiables que celles collectées par l’INSEE. En effet, tous les habitants et tous les locaux d’habitation sont concernés et cela tous les ans.
![]() Pour aller plus loin
Pour aller plus loin
![]() Documentation du recensement de la population (INSEE)
Documentation du recensement de la population (INSEE)
RPLS
Les chiffres du répertoire des logements locatifs des bailleurs sociaux (RPLS) à l’échelle communale ne sont pas les mêmes que ceux présentés dans la base IMOPE. Pourquoi ?
![]() Réponse, en bref
Réponse, en bref
Cette divergence est liée au fait que certains logements de bailleurs sociaux ont une adresse non ou mal renseignée. À l’échelle nationale 71,93% des logements du parc social possèdent une adresse qualifiée et standardisée, et peuvent donc être géolocalisées (4,1 millions de logements dans le référentiel national à l’adresse, pour les 5,7 millions déclarés par les sources
ministérielles). Les traitements réalisés par U.R.B.S. ne peuvent souvent pas reconstituer l’adresse exacte des autres logements. Par exemple, si les logements sont localisés à l’échelle de la commune uniquement, il nous est impossible de les géolocaliser plus précisément.
Ainsi, il est normal d’observer un décalage entre le nombre de logements comptabilisés dans la base IMOPE et la réalité dont vous pouvez avoir connaissance par ailleurs.
Un autre biais pouvant expliquer ces décalages concerne la dénomination des bailleurs sociaux. Ceux sont assez souvent issus de fusions et/ou ont historiquement changé de nom. Cependant les données ne sont pas systématiquement actualisée. Par exemple, on retrouve parfois un nom qui n’est plus officiel depuis plus de 30 ans. De nouveau, des pertes d’information peuvent résulter de ces imprécisions des données sources. URBS essaye autant que possible de pallier à cette problématique en sondant
l’historique et les liens possibles (filiales, fusions, …) des noms de
personnes morales. Mais ces éléments ne peuvent être automatisés en
l’état (c’est l’un des objectif du groupe de travail sur le référentiel
national des bailleurs sociaux dans lequel nous sommes mobilisés :
pouvoir tracer et bancariser plus précisément cette historique)
![]() Pour aller plus loin
Pour aller plus loin
![]() Documentation du RPLS
Documentation du RPLS