Vous étiez plus de 150 inscrits au Webinaire de présentation des nouvelles données EMMA ce jeudi 22 janvier 2026. Retour en vidéo sur ce temps de présentation, d’échanges et sur votre participation active.
Vidéo

Contexte du webinaire
Pourquoi présenter EMMA maintenant ?
Si nous communiquons aujourd’hui sur ces nouvelles données socio-économiques, c’est parce qu’elles ont été challengées par le terrain depuis plus d’un an. Depuis 2025, EMMA a été déployée en conditions réelles auprès de multiples acteurs territoriaux et leurs partenaires, sur des cas d’usage variés : lutte contre la précarité énergétique, maintien à domicile, campagnes d’aller-vers, politiques de l’habitat…
Le résultat ? Des retours opérationnels probants qui confirment la robustesse des données : doublement des taux de contact et d’accompagnement dans les campagnes de terrain (ex. sur Besançon dans le cadre de repérage de la précarité avec Stop Exclusion Energétique et La Poste : de 30% à 53%), ciblage affiné des ménages éligibles, et amélioration significative de l’efficacité des actions publiques sur plusieurs territoires.
EMMA n’est donc pas qu’un modèle validé « en laboratoire » : c’est une solution éprouvée en contexte opérationnel, sur plusieurs territoires et plusieurs cas d’usage depuis un an.
Le besoin auquel répond EMMA
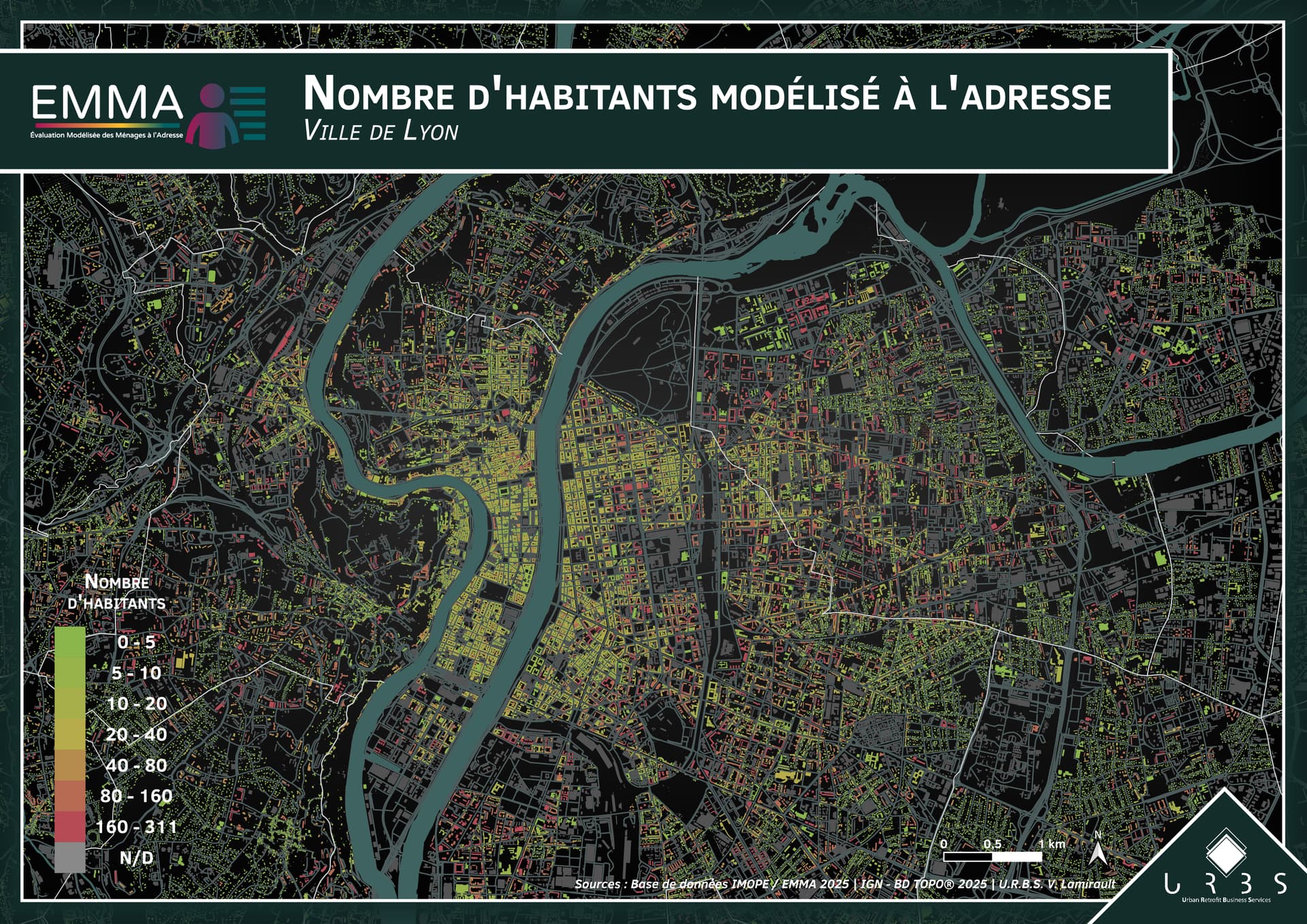
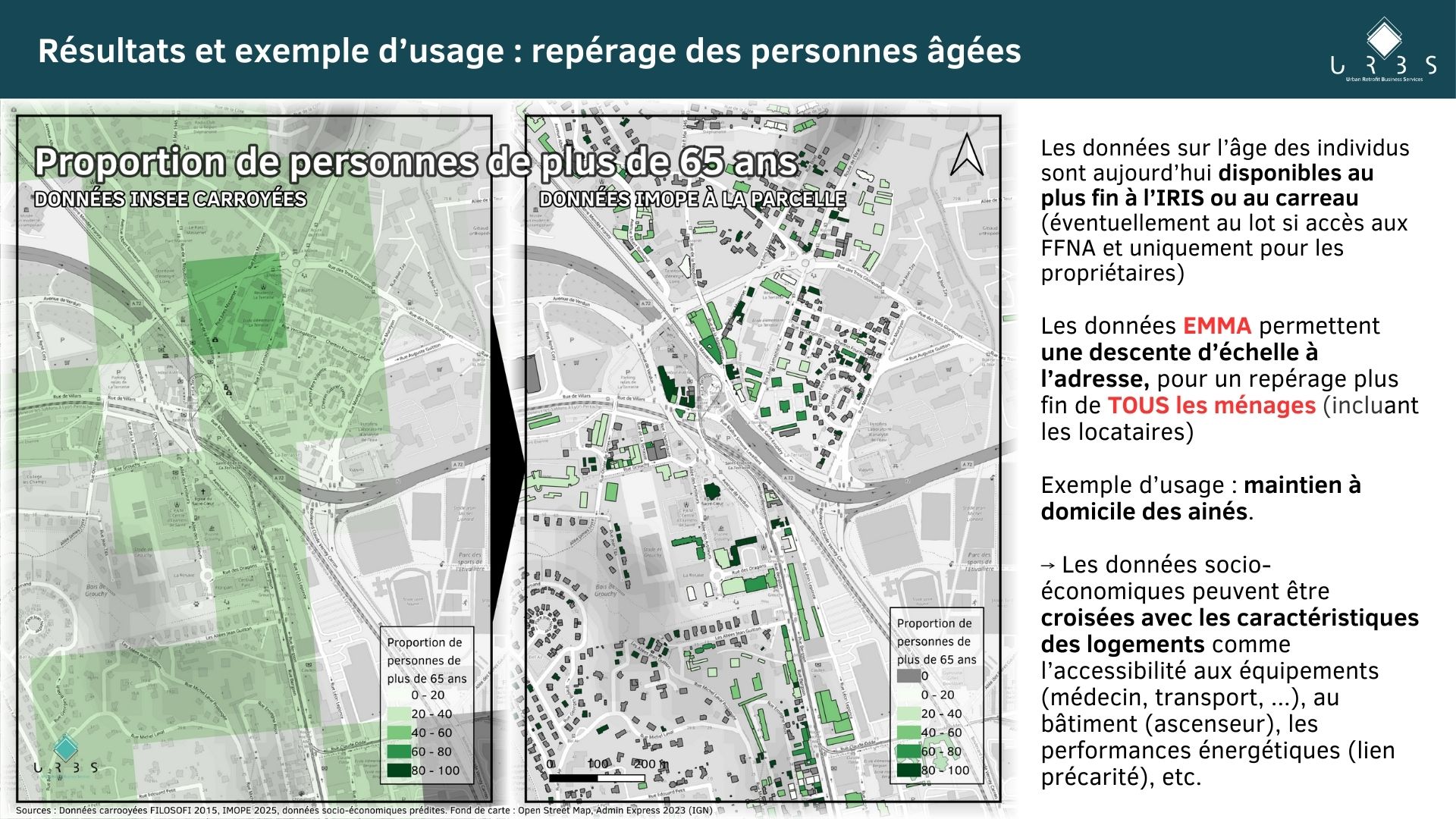
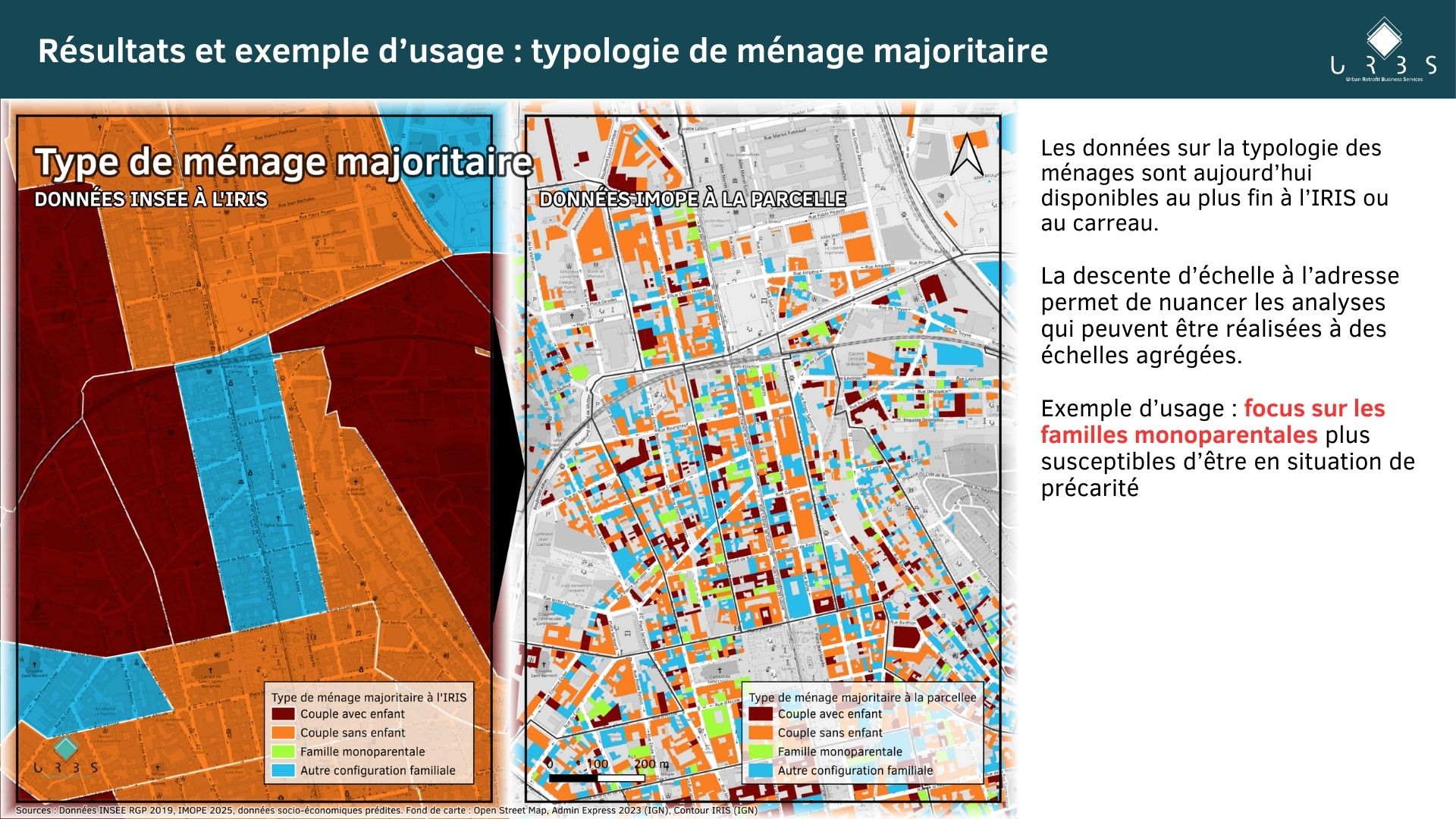
Les caractéristiques socio-économiques des occupants ne sont connues qu’à l’échelle du carreau (données carroyées produites par l’INSEE) ou de l’IRIS, donnant une vision globale du contexte dans lequel s’inscrit le bâtiment ou l’adresse considérée. Pour autant, la connaissance de ces caractéristiques à une maille plus fine permet de donner une dimension nouvelle à la connaissance du parc bâti et de venir en appui aux politiques publiques de l’habitat. Par exemple, cela permet d’affiner les stratégies de rénovation énergétique des bâtiments avec un ciblage en fonction de la structure de la population, du niveau de revenu ou de la taille des ménages.
![]()
Intéressé par ces données ?

Méthodologie
Afin de prédire les caractéristiques socio-économique pour chacune des adresse avec logement d’habitation de la base IMOPE, nous nous fondons sur l’hypothèse selon laquelle il existe une corrélation entre les caractéristiques d’un logement et le profil des ménages qui l’occupe.
Connaissant les caractéristiques des ménages, on cherche donc à les associer à des logements dont on connait également les caractéristiques. Pour se faire, on s’appuie sur deux bases de données :
- La base de données IMOPE, caractérisant le parc de locaux finement sous toutes ses dimensions. Dans cette base les logements sont géolocalisés à l’échelle de l’adresse. Le millésime utilisé est le millésime 2025.
- La base des fichiers détails des logements de l’INSEE, base qui décrit le parc de logement et y associe les caractéristiques socio-démographiques des ménages qui les habitent. Dans cette base les logements sont géolocalisés à l’échelle de l’IRIS. Pour les prédictions 2025, le millésime utilisé est le millésime 2021, plus récent millésime disponible.
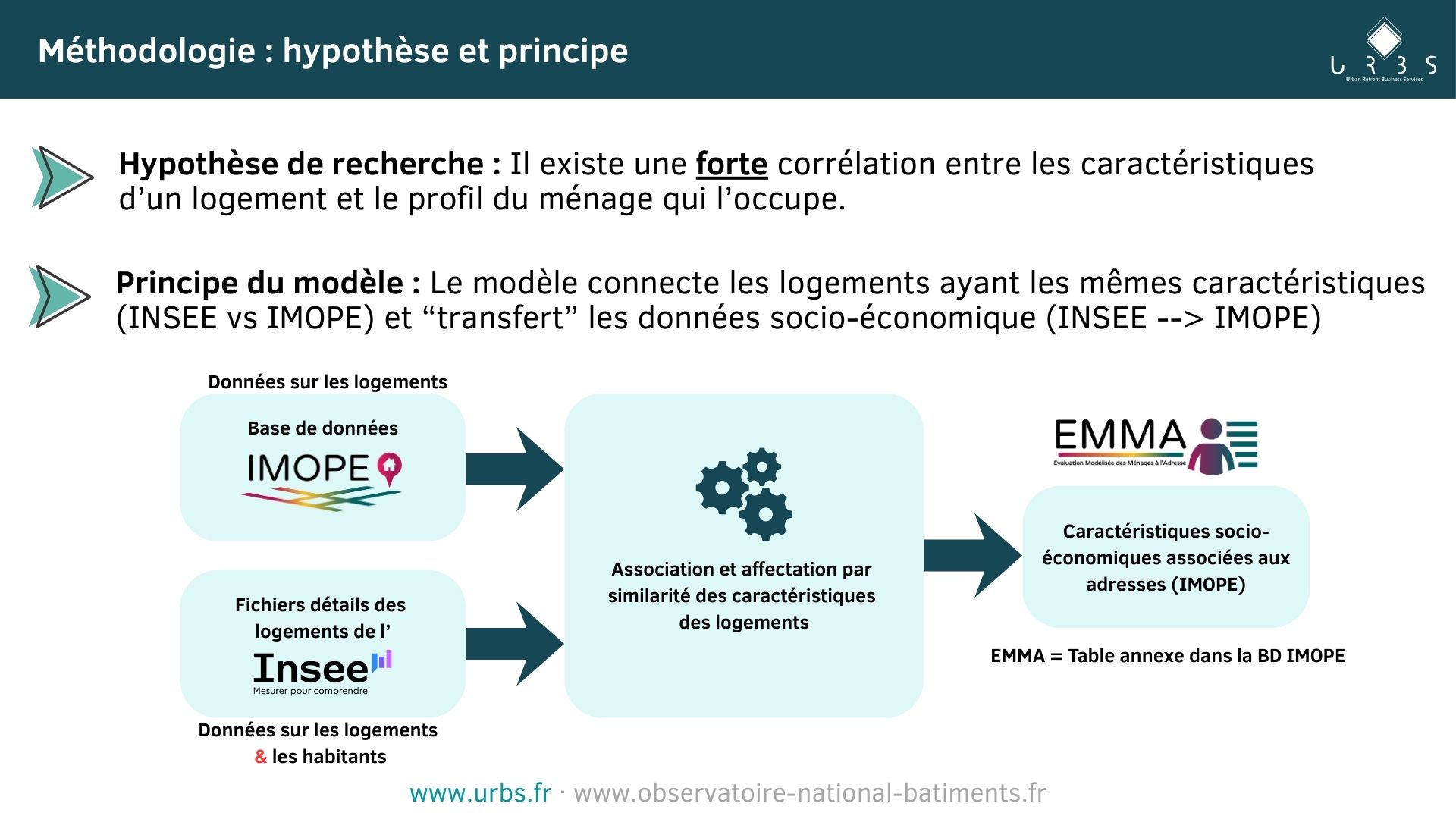
Nous utilisons un indice de similarité pour calculer les similitudes entre les logements issus des fichiers détails de l’INSEE et les locaux de la base IMOPE. Cette similitude est calculée sur une sélection de variables dont les définitions dans les deux bases sont similaires et parmi lesquelles on a la période constructive, la typologie de logement ou encore la classe de surface. On en choisit ensuite un parmi les plus similaires selon une stratégie d’affectation définie et duquel on récupère les caractéristiques socio-économiques.
Le modèle de prédiction concerne uniquement le périmètre suivant : logement d’habitation de type résidence principale étant soit une maison, soit un appartement, et identifié comme non vacant. À l’échelle de la France métropolitaine, cela concerne environ 30 millions de logements pour un peu plus de 18 millions d’adresses.
Six variables sont modélisées dans la base IMOPE :
- Le nombre de personnes des ménages (5 modalités : 1, 2, 3, 4, 5 ou plus)
- L’âge de la personne de référence du ménage (6 modalités : moins de 24 ans, 25-39 ans, 40-54 ans, 55-64 ans, 65-79 ans, plus de 80 ans)
- Le statut d’activité de la personne de référence du ménage (6 modalités : emploi sans limite de durée, emploi avec limite de durée, emploi non salarié, retraité, chomeur, autre inactif)
- Le statut conjugal du ménage (3 modalités : famille monoparentale, couple sans enfant, couple avec enfant)
- Le nombre d’enfant(s) dans le ménage (3 modalités : 1 enfant, 2 enfants, 3 enfants ou plus)
- Le nombre d’actif(s) dans le ménage (3 modalités : 1 actif, 2 actifs, 3 actifs ou plus)

Ces variables sont disponibles dans la table annexe « menage ». Dans cette table, chaque modalité fait l’objet d’une colonne et renseigne le nombre de logement de l’adresse concernée par la modalité.
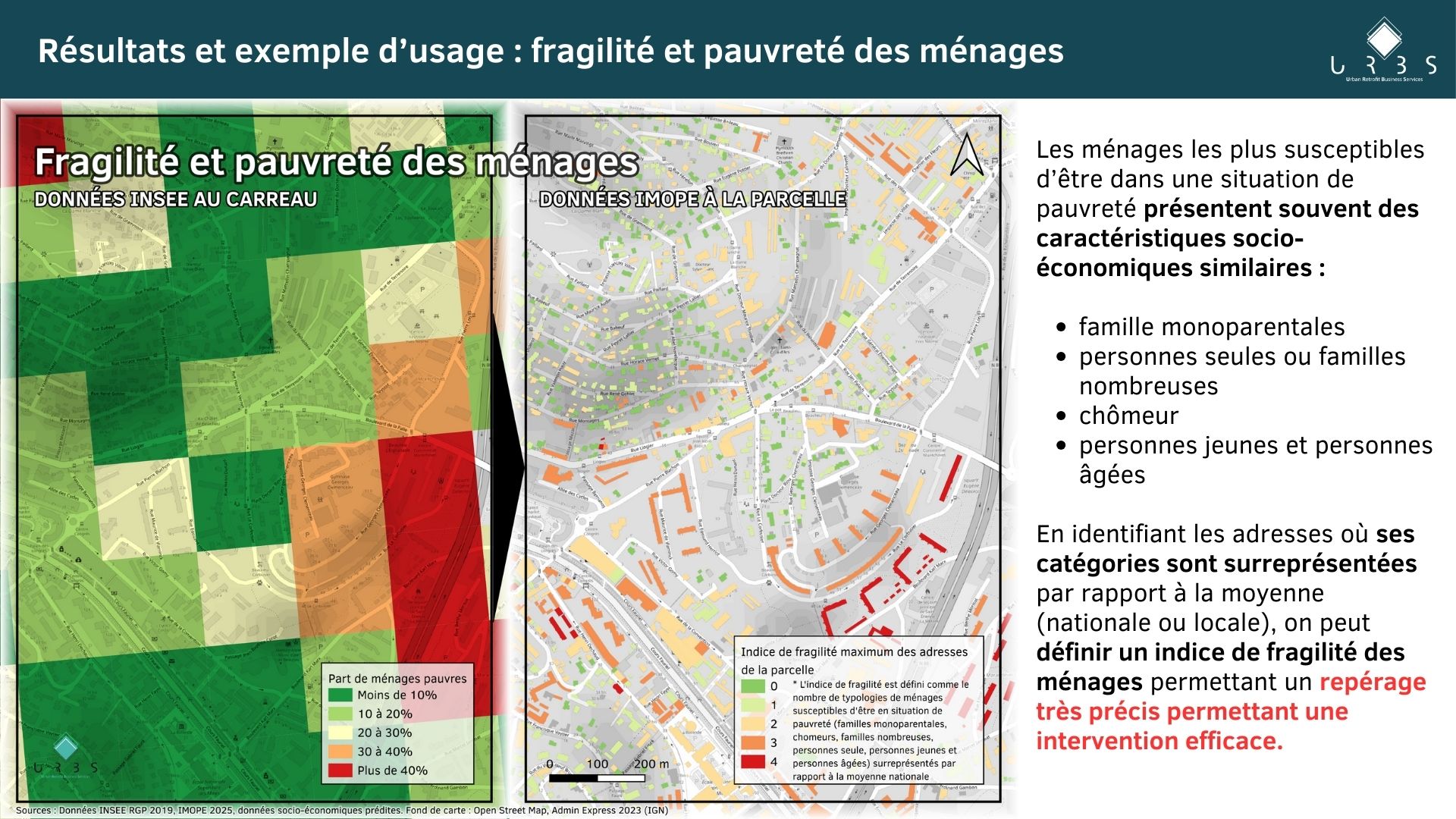
Exemples d’usages

Vos questions
De nombreuses questions ont été posées au cours du webinaire. Nous les avons récapitulées, et avons complété les réponses apportées lors des échanges oraux.
Est-ce que le modèle a été recalé sur les résultats de l’INSEE à l’échelle de l’IRIS et des carreaux ?
Oui, nous avons développé plusieurs indicateurs de fiabilité :
- Probabilité de bon choix : permet de qualifier le choix des caractéristiques socio-économiques dans le cas où plusieurs logements maximisent l’indice de similarité. Dans 3 cas sur 4, on réattribue le bon logement.
- Indice de similarité : permet de qualifier la similitude entre les logements INSEE et les logements IMOPE. C’est une mesure synthétique de la qualité de l’appariement. L’indice de similarité moyen est de 94%.
En réagrégeant les données, on retrouve les distributions de l’INSEE (iris, carreaux, communes, EPCI, département) avec environ 90 % à 96 % de similitude selon les indicateurs.
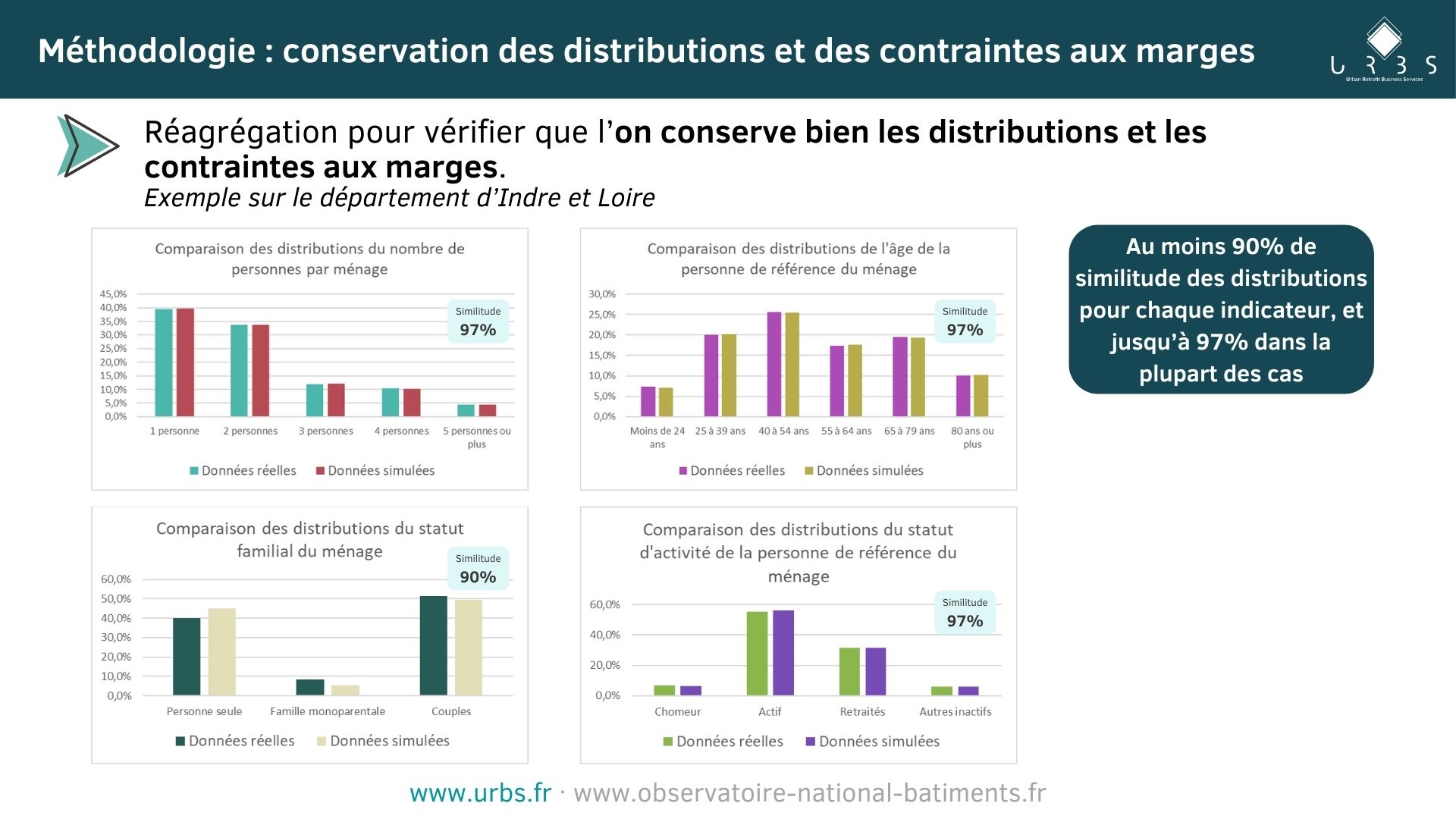
Deux raisons principales expliquent le fait qu’on ne retrouve pas une correspondance à 100% des distributions :
- Différence de millésimes entre les données INSEE (2016-2020) et IMOPE (2024/2025).
- Définitions légèrement différentes des variables entre bases IMOPE et INSEE.
Nous avons aussi réalisé une comparaison avec les fichiers fonciers non anonymisées pour l’âge des propriétaires :
- l’identification des personnes de plus de 65 ans est correcte dans environ 7 cas sur 10.

Grâce à des partenariats avec La Poste, où des facteurs ont vérifié avec les ménages, nous avons pu comparer plusieurs indicateurs (sociaux et techniques) avec des données réelles. Les taux de concordance sont plutôt bons, même si des écarts peuvent exister à cause de l’ancienneté des données (recensement).
Chaque modalité (indicateur) est une colonne dans la base de données.
Ainsi, pour l’habitat collectif, on a une distribution des caractéristiques des ménages** comme on pourrait l’avoir à une échelle agrégée.
Il y a deux vecteurs de mise à disposition :
- Livraison de jeu de données (format dump ou GeoPackage) : disponible dès aujourd’hui, utilisable au niveau adresse.
- Intégration dans l’ONB+ : données cartographiques et tableaux de bord automatiques, ces données seront disponibles dans l’application au printemps.
N’hésitez pas à nous contacter : contact@urbs.fr
- Nous réalisons une attribution statistique et il n’y a pas de levée d’anonymat ni collecte de données personnelles individuelles.
- Les données socio-économiques Emma sont destinées aux ayants droit (ceux qui peuvent accéder aux fichiers fonciers non anonymisés) pour outiller les politiques publiques. Nous avons fait le choix de ne pas autorisé un suage commercial de ces données.
Comme détaillé dans la présentation, nous utilisons un indice de similarité basé sur les caractéristiques communes des logements INSEE et des locaux IMOPE. L’appariement se fait à l’échelle du local IMOPE, qui intègre des données foncières mais aussi d’autres données techniques (chauffage, énergie, etc.) retraitées par URBS. Sans cette base enrichie, l’appariement serait moins fiable.
Les données INSEE mobilisées sont localisées à l’échelle de l’IRIS.
On associe donc les logements IMOPE et INSEE au sein du même IRIS.
- L’INSEE ne recense qu’une partie de la population, mais applique des pondérations pour estimer la représentativité. De notre côté nous utilisons ces poids pour retrouver une estimation du nombre total de ménages. A noter que pour des raisons d’anonymat, l’INSEE retire de ses fichiers détails tous les ménages trop particulier ou facilement identifiables.
Nous réalisons une mise à jour annuelle, car la base IMOPE évolue chaque année. Les fichiers détails sont mis à jour avec un pas de temps variable : 2019, 2021, 2022 constituent les trois derniers millésimes.
À partir des données adresse, on peut agréger à l’échelle d’une parcelle, IRIS, commune, quartier prioritaire, zone de sécurité, etc. Cela permet des rapports très fins ou plus agrégés selon les besoins.
Les données INSEE contiennent ces informations, qui se retrouvent dans la modélisation. On peut aussi étudier la suroccupation ou la sous-occupation des logements grâce à différents attributs (taille, superficie fiscale, etc.).
![]() Pour aller plus loin : Données socio-économiques à l’adresse
Pour aller plus loin : Données socio-économiques à l’adresse